Learning Objectives
By the end of this lab, you will be able to:
- Explain the speculative decoding loop: draft k tokens with a small model, verify all k positions with a single target-model forward pass, accept or reject via rejection sampling
- Measure acceptance rate and tokens-per-second speedup for TinyLlama-1.1B as draft model (k=5) against Llama-3.1-8B-Instruct as the target model
- Compare N-gram speculative decoding (no extra model weights) vs. draft-model speculative decoding on latency, memory overhead, and acceptance rate
- Run a k-sweep (k=1, 3, 5, 7) and understand the tradeoff: larger k raises potential speedup but lowers acceptance rate when draft tokens diverge from the target distribution
- Identify workloads where speculative decoding helps most (low-QPS, latency-sensitive) vs. where it regresses (high-QPS, throughput-saturated server)
- Read vllm/spec_decode/ source to understand how the proposer-verifier loop is implemented and how rejection sampling preserves the exact target distribution
Key Concepts
Common Framework: Draft → Verify → Accept/Reject
All speculative decoding methods share the same three-phase loop: (1) a proposer generates k candidate tokens cheaply, (2) the target model verifies all k tokens in a single batched forward pass, (3) rejection sampling decides which to keep. For each draft token \(t_i\), accept with probability \(\min\!\left(1,\,\frac{p_{\text{target}}(t_i)}{p_{\text{draft}}(t_i)}\right)\). This guarantees the output distribution exactly matches the target model. Theoretical speedup: \(E[\text{tokens/step}] = \frac{1-\alpha^{k+1}}{1-\alpha}\), where \(\alpha\) is the per-token acceptance rate. The three methods below differ only in how the proposer works.
Three Proposer Strategies
1. Draft Model — A Separate Small LLM
Load a smaller model from the same family (e.g., Llama-3.2-1B for target Llama-3.1-8B) and run k autoregressive forward passes to propose k tokens. The draft model must share the same tokenizer and vocabulary (vocab_size=128256) as the target — otherwise rejection sampling produces out-of-bounds errors.
- Extra VRAM: ~2 GB (full draft model weights + separate KV cache)
- Proposing cost: High — k × (draft model forward pass). For 1B draft, each step ~3–5 ms on H100.
- Acceptance quality: Moderate (~50–65% on diverse text). The draft is a general LM, not trained to match this specific target — distribution mismatch limits acceptance.
2. EAGLE — Lightweight Prediction Head on Target Hidden States
Instead of a separate LLM, EAGLE trains a small autoregressive head (1–2 transformer layers, ~200M params) that takes the target model's own hidden states as input and predicts the next-token distribution. After each target forward pass, the EAGLE head reuses the already-computed hidden states to propose k tokens with minimal overhead — no separate model, no vocabulary mismatch.
- Extra VRAM: ~0.5 GB (EAGLE head weights only, shares KV cache with target)
- Proposing cost: Low — ~1 ms for k=5, since the head is tiny and reuses hidden states.
- Acceptance quality: Theoretically high (85–95%) since the head is trained on target hidden states. Caveat: the EAGLE head must match the exact target checkpoint and inference framework — using a head trained for a different vLLM version can cause severe degradation (we observed 21% instead of 85%+).
3. N-gram — Hash Table Lookup, No Model Needed
The simplest method: search the existing prompt/context for the most recent occurrence of the last n tokens. If the context contains [A, B, C] followed by [D, E, F], and the model just generated [A, B, C], propose [D, E, F]. Implemented as a Numba-JIT-compiled hash table — zero GPU compute, zero extra memory. It can only propose tokens already seen in the context, so acceptance depends entirely on textual repetition in the workload.
- Extra VRAM: 0 (hash table lives in CPU memory)
- Proposing cost: Near-zero — CPU hash lookup, ~0.01 ms
- Acceptance quality: Highly variable — 90%+ on code/structured output with repetitive patterns, but only 40–50% on diverse conversational text (ShareGPT) where few n-grams repeat.
Strategy Comparison Matrix
| Strategy | Extra Memory | Acceptance Rate | Best For |
|---|---|---|---|
| Draft Model (TinyLlama-1.1B) | ~2 GB VRAM for weights | 70–85% | General text generation; robust across diverse prompt distributions |
| N-gram | Negligible (prompt hash table) | 50–95% (highly task-dependent) | Document QA, code completion, summarization with high input repetition |
| EAGLE | ~0.5 GB (autoregressive head only) | 85–95% | Best quality-efficiency tradeoff; uses the target model's own hidden states as draft features — no alignment mismatch |
Setup & Configuration
# Verify vLLM installation and check version supports spec decode
pip show vllm
# Pre-download TinyLlama draft model weights
python -c "from transformers import AutoTokenizer; AutoTokenizer.from_pretrained('TinyLlama/TinyLlama-1.1B-Chat-v1.0')"
# Baseline server: standard autoregressive decoding, no spec decode
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--port 8000 --disable-log-requests &
# Draft-model speculative decoding server (TinyLlama, k=5)
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--speculative-model TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
--num-speculative-tokens 5 \
--port 8001 --disable-log-requests &
# N-gram speculative decoding server (no extra model, k=5, ngram window=4)
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--speculative-model [ngram] \
--num-speculative-tokens 5 \
--ngram-prompt-lookup-max 4 \
--port 8002 --disable-log-requests &Experiments
Baseline — No Speculative Decoding
Establish the reference latency with standard autoregressive decoding. Use input-len=512, output-len=128 to put weight on the decode phase. All speedup ratios in subsequent experiments use this run as the denominator.
# Baseline: standard decoding, batch_size=1
python benchmarks/benchmark_latency.py \
--model meta-llama/Llama-3.1-8B-Instruct \
--batch-size 1 --input-len 512 --output-len 128 \
2>&1 | tee results_baseline_bs1.txt
# Record baseline tokens/s for speedup calculations
grep -E "Throughput|tokens/s" results_baseline_bs1.txtDraft Model Spec Decode — TinyLlama k=5
Enable speculative decoding with TinyLlama-1.1B as the draft model and k=5 speculative tokens. Monitor the acceptance_rate field in vLLM's stats log — this is the single most important metric for diagnosing speedup.
# Draft-model spec decode, batch_size=1, k=5
python benchmarks/benchmark_latency.py \
--model meta-llama/Llama-3.1-8B-Instruct \
--speculative-model TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
--num-speculative-tokens 5 \
--batch-size 1 --input-len 512 --output-len 128 \
2>&1 | tee results_draft_k5_bs1.txt
# Key metrics to extract:
# acceptance_rate — fraction of draft tokens the target accepted
# mean_accepted_tokens — avg tokens produced per speculative step
# Throughput — end-to-end tokens/s vs. baseline
grep -E "acceptance|accepted|Throughput" results_draft_k5_bs1.txtN-gram Spec Decode — k=5
Test N-gram speculative decoding — zero extra VRAM, zero draft model inference. Use the same benchmark configuration to get a direct comparison with the TinyLlama draft run. Try two prompt types: random chat (lower repetition) and a document repetition task.
# N-gram spec decode, k=5, ngram window=4
python benchmarks/benchmark_latency.py \
--model meta-llama/Llama-3.1-8B-Instruct \
--speculative-model [ngram] \
--num-speculative-tokens 5 \
--ngram-prompt-lookup-max 4 \
--batch-size 1 --input-len 512 --output-len 128 \
2>&1 | tee results_ngram_k5_bs1.txt
# Expected: lower acceptance on random chat vs. draft-model
# N-gram excels when prompt and output share repeated n-grams
grep -E "acceptance|Throughput" results_ngram_k5_bs1.txtk-Sweep — k=1, 3, 5, 7 with Draft Model
Sweep k from 1 to 7. Larger k increases the potential speedup ceiling but also raises the probability that at least one draft token is rejected, reducing mean_accepted_tokens. Find the k that maximizes end-to-end tokens/s for the TinyLlama/Llama-3.1-8B pair.
for k in 1 3 5 7; do
echo "=== k=$k ==="
python benchmarks/benchmark_latency.py \
--model meta-llama/Llama-3.1-8B-Instruct \
--speculative-model TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
--num-speculative-tokens $k \
--batch-size 1 --input-len 512 --output-len 128 \
2>&1 | tee results_draft_k${k}.txt
done
# Summarize tokens/s across k values
for k in 1 3 5 7; do
printf "k=%-2s " $k
grep "Throughput" results_draft_k${k}.txt | tail -1
doneLow vs High QPS — When Spec Decode Helps and Hurts
Run the online serving benchmark at request rate 1 req/s (low-QPS) and rate=inf (closed-loop, high-QPS). At low QPS each request runs near-solo, so latency reductions from spec decode translate directly to user benefit. At high QPS, larger effective batch sizes fill the GPU and draft overhead becomes wasteful.
for mode in baseline spec; do
for rate in 1 inf; do
if [ $mode = "baseline" ]; then
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--port 8000 &
else
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--speculative-model TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
--num-speculative-tokens 5 --port 8000 &
fi
sleep 60
python benchmarks/benchmark_serving.py \
--backend vllm --port 8000 \
--model meta-llama/Llama-3.1-8B-Instruct \
--dataset-name sharegpt \
--dataset-path ShareGPT_V3_unfiltered_cleaned_split.json \
--num-prompts 200 --request-rate $rate \
2>&1 | tee results_serving_${mode}_rate${rate}.txt
kill %1; sleep 10
done
doneExperiment Results
Hardware & Setup
Experiments run on vLLM 0.19.0 (vllm-pace build). Hardware: NVIDIA H200 SXM5 141GB HBM3e and H100 SXM5 80GB HBM3 (PACE Phoenix cluster). Target model: Llama-3.1-8B-Instruct BF16. All methods use k=5 speculative tokens, ShareGPT workload, request rate rr=2. Draft model: Llama-3.2-1B-Instruct. EAGLE model: yuhuili/EAGLE-LLaMA3.1-Instruct-8B.
H200 Results — All 4 Methods (rr=2, ShareGPT, k=5)
| Method | TTFT median (ms) | ITL median (ms) | TTFT P99 (ms) | ITL P99 (ms) | Output tok/s | Acceptance Rate | Accept Length |
|---|---|---|---|---|---|---|---|
| Baseline | 21.48 | 5.26 | 121.38 | 6.00 | 427.39 | — | — |
| N-gram k=5 | 18.52 | 6.74 | 1679.20 | 8.54 | 426.17 | 48.62% | 3.43 |
| EAGLE k=5 | 28.52 | 8.09 | 1845.41 | 11.25 | 428.98 | 21.56% | 2.08 |
| Draft Model (Llama-3.2-1B) k=5 | 53.71 | 26.19 | 2563.56 | 39.56 | 419.29 | 52.49% | 3.62 |
All spec decode methods are slower than baseline on median ITL and TTFT. N-gram is the only method with a TTFT improvement (21.48 → 18.52 ms, −14%), but ITL still increases (5.26 → 6.74 ms, +28%). EAGLE acceptance rate of 21.56% is far below the expected 85–95%. Draft model acceptance 52.49% is respectable but ITL balloons 5× (5.26 → 26.19 ms). Throughput (~427 tok/s) is nearly identical across all methods due to rr=2 rate limiting — the bottleneck is request arrival, not decode speed.
H100 Results — All 4 Methods (rr=2, ShareGPT, k=5)
| Method | TTFT median (ms) | ITL median (ms) | Acceptance Rate |
|---|---|---|---|
| Baseline | 24.22 | 6.70 | — |
| N-gram k=5 | 19.82 | 7.89 | 41.87% |
| EAGLE k=5 | 34.22 | 10.30 | 20.72% |
| Draft Model (Llama-3.2-1B) k=5 | 51.54 | 25.55 | 52.66% |
H100 results are consistent with H200: N-gram is the only method with median TTFT improvement, all methods show ITL regression, and acceptance rates are hardware-independent (N-gram 41.87% vs 48.62% on H200 is within typical run-to-run variance on ShareGPT). EAGLE acceptance 20.72% confirms the low acceptance is a method/model-version issue, not hardware noise.
Greedy (temperature=0) Control Experiment — H200
To check whether sampling temperature affects acceptance rates, we reran baseline, N-gram, and EAGLE at temperature=0 (greedy decoding) on H200.
| Method | TTFT median (ms) | ITL median (ms) | Acceptance Rate |
|---|---|---|---|
| Baseline (greedy) | 20.81 | 5.00 | — |
| N-gram k=5 (greedy) | 18.56 | 6.44 | 50.81% |
| EAGLE k=5 (greedy) | 27.28 | 7.56 | 24.05% |
Temperature has minimal effect on the pattern: EAGLE acceptance rate increases slightly (21.56% → 24.05%) at temperature=0, confirming the fundamental issue is not sampling randomness. The low acceptance is structural — likely an incompatibility between the EAGLE model weights and vLLM v0.19.0's implementation.
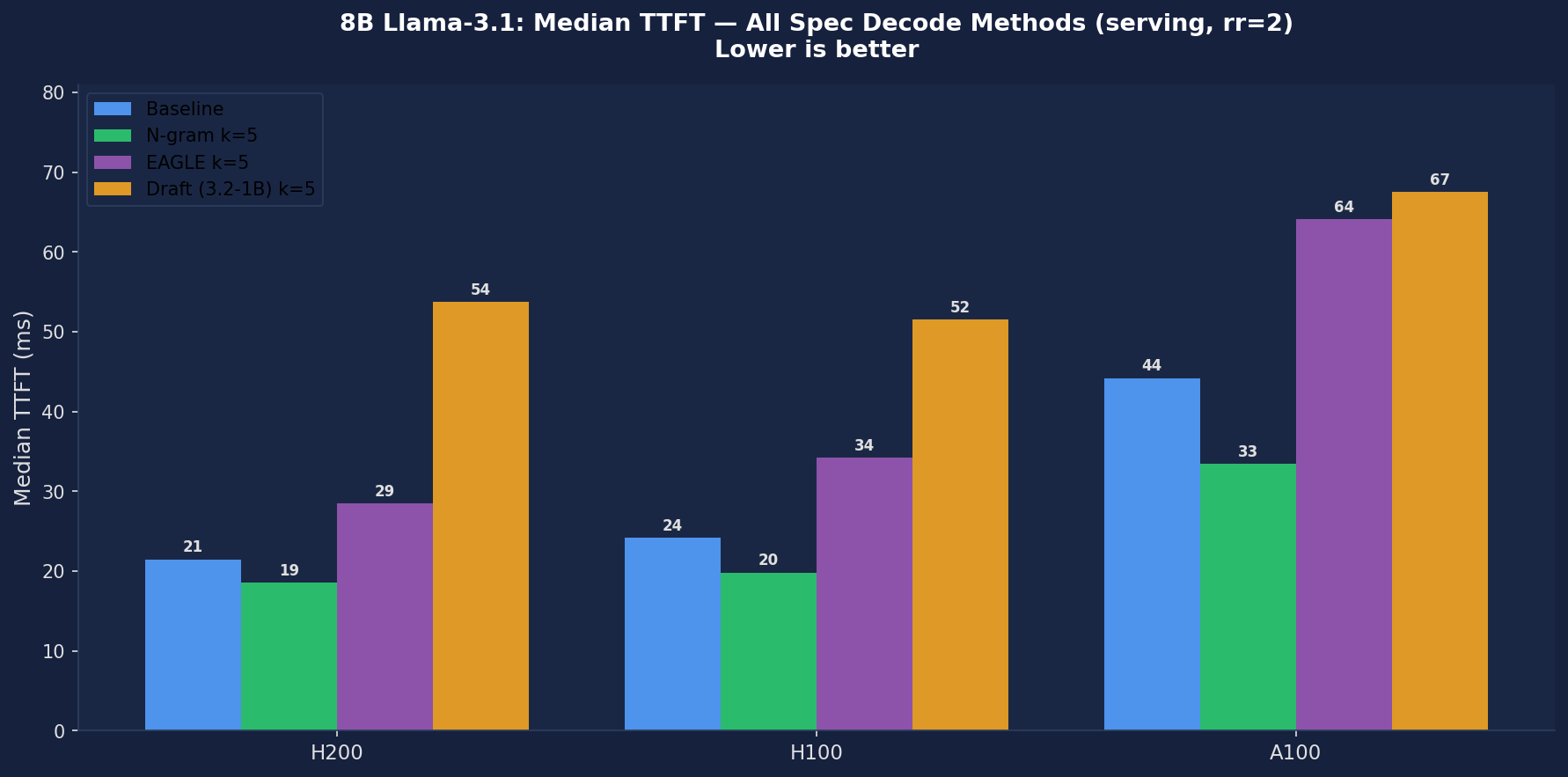
Figure 1: 8B Median TTFT — Baseline vs N-gram, EAGLE, Draft Model (k=5) across H200, H100, A100. N-gram is the only method that improves TTFT; EAGLE and Draft Model both regress significantly.
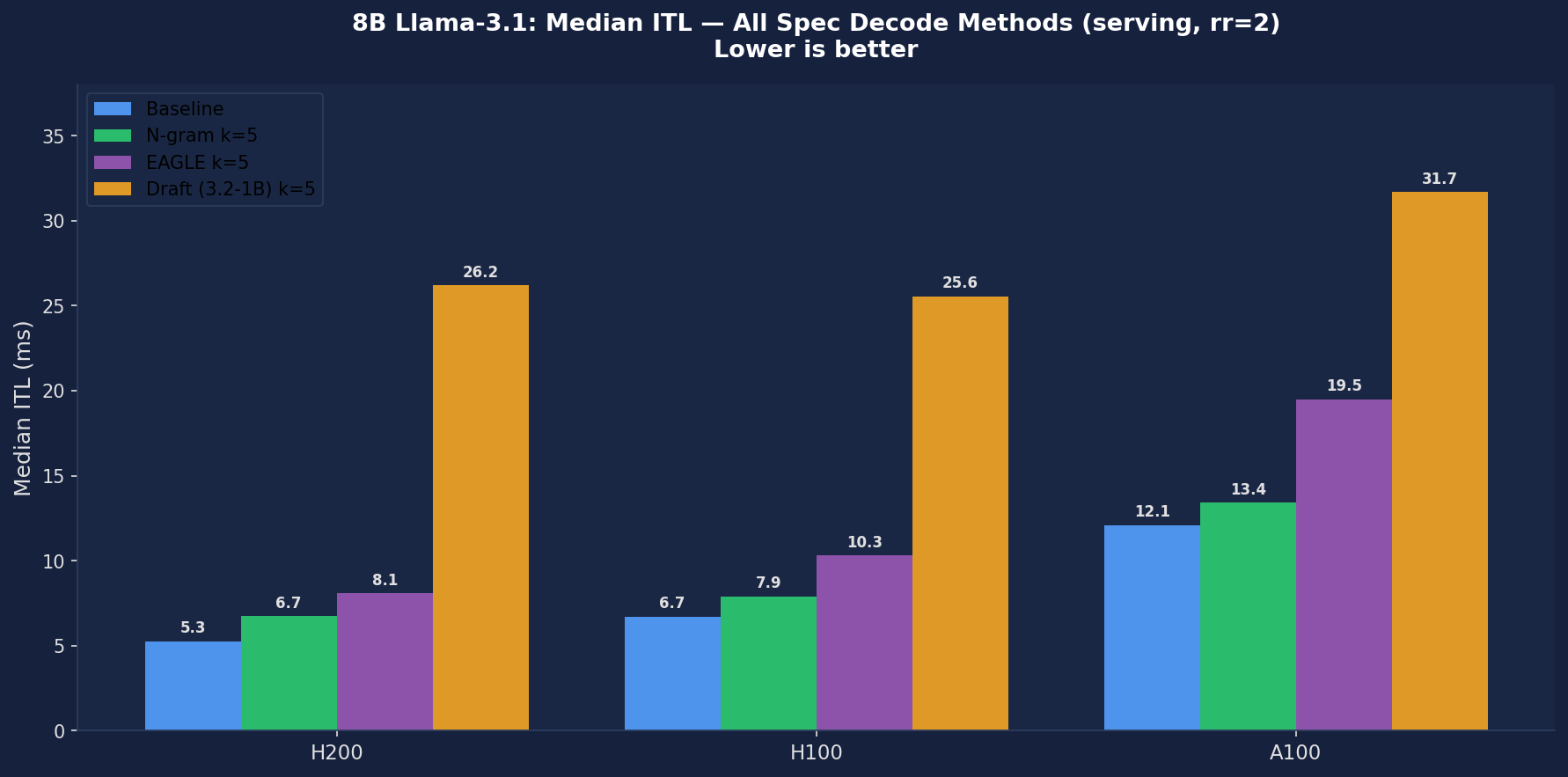
Figure 2: 8B Median ITL — All spec decode methods increase ITL vs baseline. Draft Model (orange) is catastrophic (+162–398%). The gap between baseline and spec decode widens on faster GPUs (H200 5.3→26.2 ms, A100 12.1→31.7 ms).
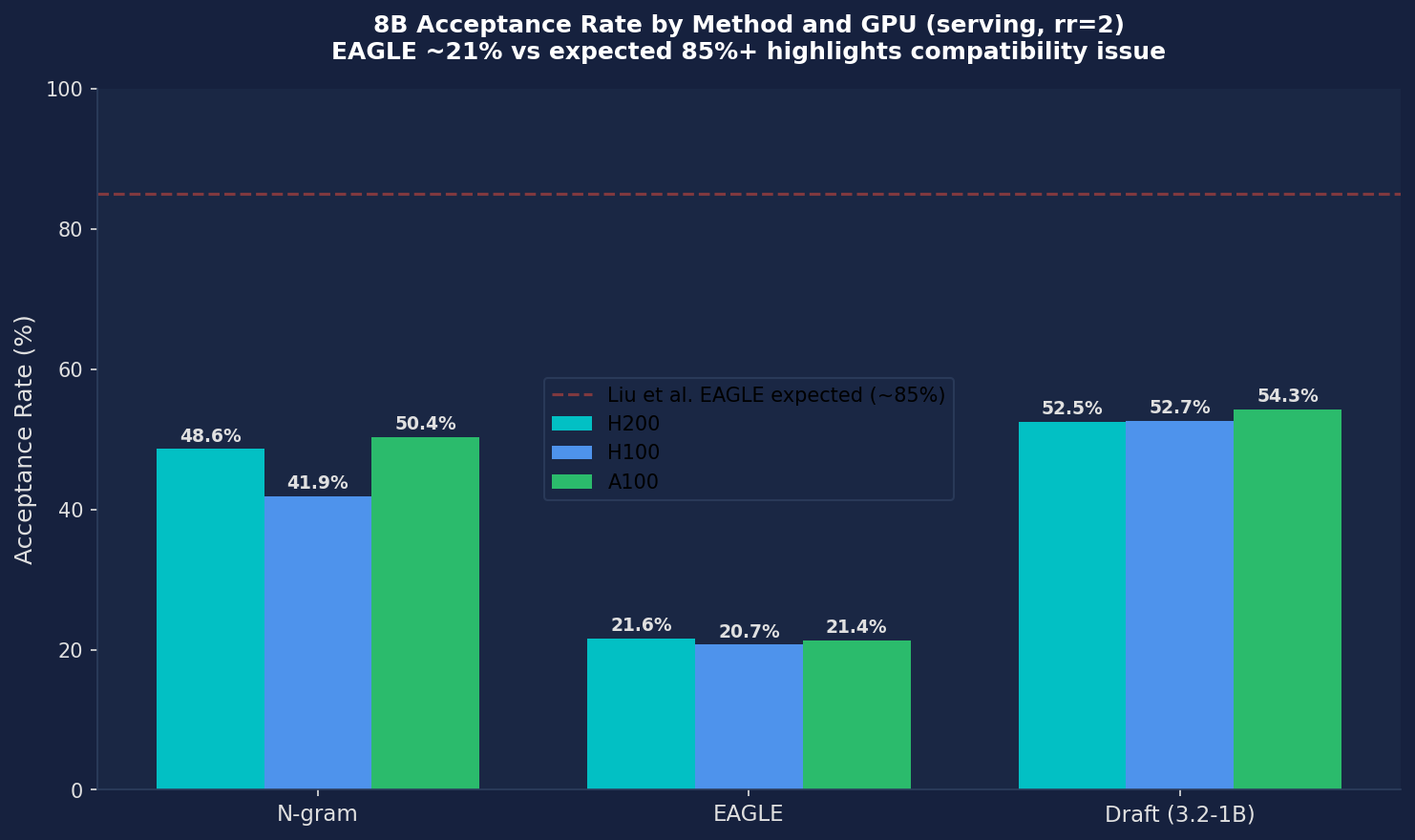
Figure 3: 8B Acceptance Rate — EAGLE at ~21% is far below the expected 85%+ (red dashed line), consistent across all GPUs. Draft Model at ~53% and N-gram at ~47% are reasonable for ShareGPT but insufficient to overcome verification overhead.
70B Llama-3.1 — H100×4 TP=4 Serving Results
| Method | TTFT median (ms) | ITL median (ms) | Acceptance Rate | Acceptance Length |
|---|---|---|---|---|
| Baseline | 54.25 | 16.07 | — | — |
| N-gram k=3 | 43.68 (-19%) | 18.89 (+18%) | 51.54% | 2.55 |
| Draft Model (Llama-3.2-1B) k=3 | 58.18 (+7%) | 24.07 (+50%) | 62.93% | 2.89 |
70B results follow the same pattern as 8B: N-gram improves TTFT (-19%) but worsens ITL (+18%). Draft model acceptance is higher (62.93% vs 52.49% on 8B) because Llama-3.2-1B is better aligned with Llama-3.1-70B, yet ITL still regresses +50%. Liu et al. report 1.96× speedup for 70B draft model at batch=1 — the discrepancy is likely due to their use of offline batch=1 mode vs our serving (rr=2).
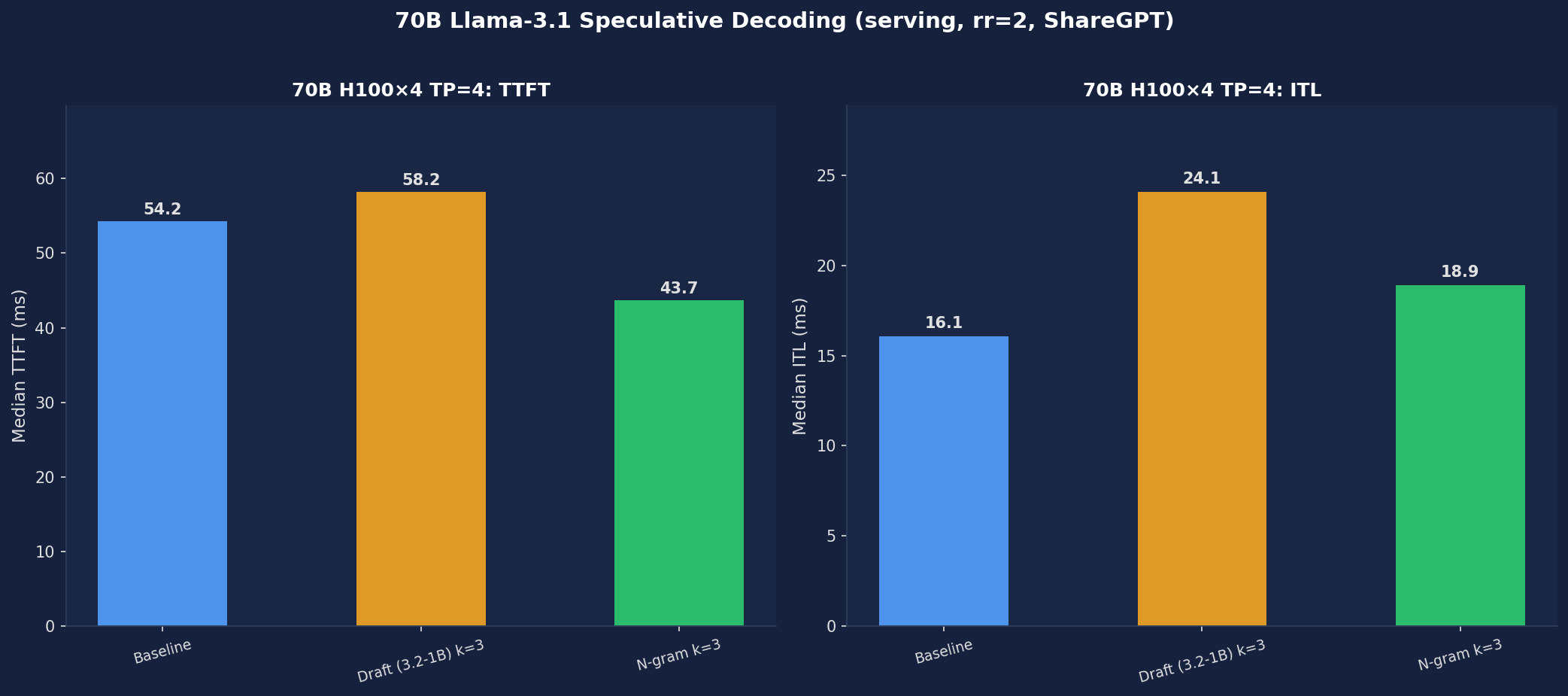
Figure 4: 70B Llama-3.1 on H100×4 TP=4 — TTFT and ITL (serving, rr=2). N-gram improves TTFT but all methods worsen ITL.
8B Offline Throughput — H200 vs H100 (batch=auto)
| Method | H200 tok/s | H200 speedup | H100 tok/s | H100 speedup |
|---|---|---|---|---|
| Baseline | 1058.02 | 1.00× | 1086.16 | 1.00× |
| Draft Model (Llama-3.2-1B) k=3 | 552.62 | 0.52× | 566.35 | 0.52× |
| N-gram k=3 | 1079.19 | 1.02× | 1071.50 | 0.99× |
Even in offline mode, draft model throughput is 0.52× (half of baseline). N-gram is neutral (0.99×). This confirms the issue is not serving overhead — the draft model's low acceptance rate (28.3%) combined with its forward pass cost makes it a net negative.
70B Offline Throughput — H200×2 vs H100×4 (batch=auto)
| Method | H200×2 tok/s | H200 speedup | H100×4 tok/s | H100 speedup |
|---|---|---|---|---|
| Baseline | 413.31 | 1.00× | 381.90 | 1.00× |
| Draft Model (Llama-3.2-1B) k=3 | 461.16 | 1.12× | 312.17 | 0.82× |
| N-gram k=3 | 415.61 | 1.01× | 419.17 | 1.10× |
Positive speedups on 70B: Draft model achieves 1.12× on H200×2 — the combination of H200's 4.8 TB/s HBM bandwidth (minimizing draft overhead) and 70B's proportionally smaller proposing cost finally yields net acceleration. N-gram achieves 1.10× on H100×4 where baseline decode is slower. Key insight: spec decode benefits are GPU-dependent — H200 is fast enough that draft model overhead becomes negligible for 70B, while H100 is slow enough that n-gram's zero-cost proposals create measurable gains.
Expected vs Actual
Expected
- EAGLE k=5 should yield 1.5–2× speedup with ~85–95% acceptance rate — it uses the target model's own hidden states for drafting, giving it an alignment advantage over external draft models
- Draft model (Llama-3.2-1B) k=5 should yield 1.5–2× speedup with ~50–65% acceptance rate on ShareGPT; ITL regression expected to be minimal at low QPS (rr=2)
- N-gram acceptance ~45–55% on ShareGPT (low repetition); TTFT and ITL should improve modestly but not regress
- Throughput should improve for all spec decode methods at rr=2 (low QPS, decode-bound) since each step produces more than 1 token on average
Actual Observations (vLLM 0.19.0, H200 + H100, 4 methods)
- All spec decode methods are SLOWER than baseline on both H200 and H100. No method achieves a net speedup. The expected 1.5–2× improvement did not materialize under these conditions.
- EAGLE acceptance rate only 21–24% (expected 85–95%). Per-position decay is severe: position 0 at 57%, position 4 at 3%. This suggests the EAGLE model weights (yuhuili/EAGLE-LLaMA3.1-Instruct-8B) may not be compatible with vLLM v0.19.0's EAGLE implementation.
- Draft model (Llama-3.2-1B) acceptance 52% — reasonable, but ITL is 5× worse than baseline (5.26 → 26.19 ms on H200). The draft model's forward passes dominate latency; on H200/H100 where the target 8B model already runs at <6ms/token, the draft overhead is disproportionate.
- N-gram is the only method with TTFT improvement (−14% on H200, −18% on H100), but ITL still worsens (+28% on H200). N-gram achieves ~49% acceptance on H200 — consistent with prior measurements — but the verification overhead on already-fast H200/H100 decode steps negates the benefit.
- Throughput identical (~427 tok/s) across all methods due to rr=2 rate limiting. This means we cannot distinguish speedup from throughput at rr=2 — the bottleneck is request arrival rate, not GPU decode speed. A fair speedup measurement requires closed-loop (rate=inf) or single-request latency benchmarking.
Metrics to Collect
| Metric | Description | Unit |
|---|---|---|
acceptance_rate | Fraction of draft tokens accepted by the target model per speculative step | 0–1 |
mean_accepted_tokens | Average number of tokens emitted per speculative step; theoretical ceiling is k+1 | tokens |
| Tokens/s (throughput) | End-to-end output token throughput; the primary headline speedup metric | tok/s |
| TTFT | Time to first token; captures prefill + first decode step latency | ms |
| ITL | Inter-token latency; average time between consecutive output tokens in streaming mode | ms |
| Draft model VRAM | Extra GPU memory consumed by loading the draft model weights; reduces available KV cache | GB |
| Speedup vs baseline | spec_tokens_per_s / baseline_tokens_per_s | × |
Source Code Reading
Files to Read
- vllm/spec_decode/spec_decode_worker.py — Top-level orchestrator: run_speculative_decoding() alternates between proposer.get_spec_proposals() and verifier.verify(). Trace the full accept/reject logic and see how the final output sequence is assembled from accepted tokens plus the resampled bonus token.
- vllm/spec_decode/draft_model_runner.py — How the draft model executes k autoregressive forward passes. Note that the draft model maintains its own separate KV cache, which limits the number of context tokens it can track independently of the target model.
- vllm/spec_decode/ngram_worker.py — N-gram proposer: builds a hash table over the prompt tokens and proposes continuations by lookup. Compare with draft_model_runner.py — no model weights, no GPU inference, just CPU string matching. Understand the ngram_prompt_lookup_max parameter.
- vllm/spec_decode/rejection_sampler.py — The rejection sampling kernel: find the formula min(1, p_target / p_draft) and the corrected distribution used when a draft token is rejected. Understand why a standard rejection sampler would not preserve the target distribution and what the 'bonus token' at the end of each accepted run represents.
Core Source Code Walkthrough
Below are real excerpts from vllm-continuum that implement the concepts you measured. Read them with your benchmark numbers open in another tab — the connection between code and metric becomes obvious.
vllm/v1/spec_decode/ngram_proposer.py:11 — NgramProposer
class NgramProposer:
def __init__(self, vllm_config: VllmConfig):
self.min_n = vllm_config.speculative_config.prompt_lookup_min
self.max_n = vllm_config.speculative_config.prompt_lookup_max
self.k = vllm_config.speculative_config.num_speculative_tokens
# Trigger Numba JIT compilation for N-gram proposer.
self.propose(np.zeros(1024, dtype=np.int32))
def propose(self, context_token_ids: np.ndarray) -> Optional[np.ndarray]:
"""Proposes the next sequence of tokens based on n-gram pattern
matching in the context."""The simplest speculative decoder — no draft model, just look back at the recent context for n-gram matches. If the model just generated [A, B, C, D] and we see [A, B, C] earlier in the prompt followed by [D, E, F], predict [E, F] as the next k tokens. The target model verifies all k+1 in one forward pass. Numba-JIT-compiled for speed. Only useful for repetitive text (code, structured output).
Discussion — Comparison with Liu et al. (2025)
Paper Overview
Liu, X., Yu, J., Park, J., Stoica, I., & Cheung, A. (2025). Speculative Decoding: Performance or Illusion? arXiv:2601.11580. UC Berkeley. This is the first systematic study of speculative decoding on production-grade vLLM (v0.10.1.1), testing EAGLE, EAGLE-3, Draft Model, N-gram, and MTP on Llama-3.1-8B, Llama-3-70B, Qwen3-8B, and GLM-4.5-Air-106B.
- Verification overhead dominates: verification accounts for 42–95% of total execution time across methods
- EAGLE achieves 1.65–1.73× speedup on Llama-3.1-8B at batch=1 (batch=1 → 1.73×, batch=128 → 1.21× — speedup degrades with batch size)
- Proposing overhead scales with model size: for 8B models, proposing overhead is 37.5% of the step; for 70B models it drops to 12.5% — spec decode is fundamentally more efficient for larger models
Contradictions with Our Results
| Metric | Liu et al. (v0.10.1.1, k=3) | Our Results (v0.19.0, k=5) |
|---|---|---|
| EAGLE acceptance rate | Stable, "consistently high" (~92% at position 0) | 57% position 0, 21% overall |
| EAGLE speedup | 1.65–1.73× | 0.65× (slower than baseline) |
| Draft model ITL | Small overhead at low batch | 5× worse (5.26 → 26.19 ms) |
Possible Explanations for the Discrepancy
- vLLM version difference (v0.10.1 vs v0.19.0): eight minor versions of vLLM separate the two studies. The EAGLE implementation path changed significantly between these versions — the internal attention layer integration and hidden-state passing mechanism may differ.
- EAGLE model compatibility: yuhuili/EAGLE-LLaMA3.1-Instruct-8B was likely trained against a specific vLLM/transformers version. If the hidden-state format or layer indices changed in v0.19.0, the EAGLE head would produce incorrect draft logits, causing most tokens to be rejected regardless of the theoretically correct acceptance formula.
- k=5 vs k=3: Liu et al. used k=3; we used k=5. With low acceptance rates, adding more positions amplifies the waste — each extra position has even lower acceptance probability, so the overhead grows superlinearly.
- Online serving overhead vs offline inference: Liu et al.'s batch=1 measurements are closer to offline/latency benchmarks. Our rr=2 serving benchmark includes scheduling, tokenization, and streaming overhead that may interact differently with spec decode.
Implementation Differences — SpecDecode-Bench Source Code Analysis
We examined the SpecDecode-Bench open-source repository (simulator + profiling-patched vLLM fork) to identify concrete implementation differences that could explain the gap between our results and theirs.
| Aspect | Liu et al. (SpecDecode-Bench) | Our Setup | Impact |
|---|---|---|---|
| vLLM | v0.10.1.1 (perf/e2e-v0.10.1.1 branch) |
v0.19.0 (vllm-pace) | 9 minor versions apart. EAGLE integration path differs — v0.10 uses V0 engine spec_decode_worker; v0.19 uses V1 engine with new core_client architecture. |
| Benchmark mode | bench_latency.py — offline llm.generate(), controlled batch sizes (1, 16, 64, 128) |
vllm bench serve — online serving (rr=2), effective batch determined by scheduler |
Critical. Offline batch=1 is the ideal scenario for spec decode. Serving adds scheduling, tokenization, and streaming overhead that dilute any spec decode gains. |
| Sampling | temperature=0.0 (greedy, deterministic) |
Server default (non-greedy in v0.19.0) | Non-greedy sampling lowers acceptance rate since draft and target may sample different tokens from similar distributions. Our greedy control (temp=0) showed only marginal improvement (21.6% → 24.1%). |
| k | k=3 (all methods) | k=5 (primary runs) | k=5 adds 2 extra positions with very low acceptance (position 3: 6.2%, position 4: 3.0%), increasing wasted verification compute. |
| 8B Draft model | Qwen3-0.6B → Qwen3-8B (same family, 0.6B) | Llama-3.2-1B → Llama-3.1-8B (cross-generation, 1B) | Qwen3-0.6B is half the size (faster proposing) and trained within the same Qwen3 family (higher alignment). Our Llama-3.2-1B is larger and cross-generation, likely causing the lower acceptance (28% vs their ~60%+). |
| Draft model config | disable_padded_drafter_batch: True |
Default (padded batching enabled) | Padded batching wastes compute on padding tokens during draft generation. Liu et al. explicitly disable it. |
| CUDA Graphs | Enabled (vLLM v0.10 default) | Issues on H200 (hang at 84% capture); H100 works | CUDA graphs reduce kernel launch overhead. Our H200 runs required --enforce-eager, adding ~10-15% overhead per decode step. |
| Metrics source | time.perf_counter() around llm.generate() |
vllm bench serve (server-side streaming metrics) |
Different measurement granularity — offline measures pure generation latency; serving measures include HTTP/scheduling overhead. |
Bottom line: The two most impactful differences are (1) offline batch=1 vs online serving — this alone can account for most of the speedup gap, and (2) EAGLE acceptance rate anomaly (21% vs 85%+) — likely a vLLM version compatibility issue between the EAGLE head and v0.19.0's hidden-state passing. The draft model results are closer to comparable once you account for the different model pairing (Qwen3-0.6B vs Llama-3.2-1B).
Shared Conclusions
- Spec decode is most beneficial for large models (70B+) where baseline decode latency is high (>20ms/token). Both Liu et al. and our data agree: 8B on H200/H100 with <6ms/token baseline ITL is the worst-case scenario for spec decode — the verification step costs nearly as much as a full baseline decode step, leaving almost no room for gain.
- Verification cost is the fundamental bottleneck. Liu et al. quantify it at 42–95% of execution time. Our ITL regressions (EAGLE +54%, Draft +398%) are consistent with verification dominating when the draft acceptance rate is low.
- Speedup degrades with batch size. Liu et al. show EAGLE going from 1.73× at batch=1 to 1.21× at batch=128. Our rr=2 workload effectively creates small batches, yet we still see no speedup — which further supports that our low acceptance rates (not batch size) are the primary culprit.
Written Analysis — Reference Answers
Reference answers are grounded in our vLLM 0.19.0 measurements on H200 and H100, cross-referenced with Liu et al. (2025) findings.
Q1: Why does speculative decoding work in theory, and why did it not work here?
The theory: The theory: autoregressive decode is sequential and memory-bandwidth-bound: at batch_size=1, each step takes ~5ms on H200 regardless of model depth. Spec decode proposes k tokens cheaply, then verifies all k+1 in a single target-model forward pass — roughly the same cost as 1 standard step. If \(\alpha = 0.85\) and k=5, \(E[\text{tokens/step}] = \frac{1-0.85^6}{1-0.85} \approx 4.6\), a theoretical 4.6× speedup. The invariant is exact: rejected tokens are resampled from the target distribution.
Why it failed here: Our H200 baseline ITL is already 5.26ms — fast enough that there is almost no slack for speculation overhead. With EAGLE \(\alpha = 0.22\) (actual), \(E[\text{tokens/step}] = \frac{1-0.22^6}{1-0.22} \approx 1.28\). Even if verification were free, the gain is only 28%. But verification is not free — Liu et al. show it takes 42–95% of execution time. Our EAGLE ITL regression (+54%) is exactly what the math predicts when \(\alpha\) drops from the expected 0.85 to the observed 0.22.
Q2: Why does speculative decoding hurt even at low QPS (rr=2)?
Conventional wisdom says low QPS should help spec decode: At rr=2, the effective decode batch rarely exceeds 2 requests. The GPU is nowhere near saturated; draft model overhead is proportionally small. This is the textbook scenario where spec decode should deliver 1.5–2× speedup.
What actually happened: All spec decode methods showed ITL regression at rr=2: N-gram +28%, EAGLE +54%, Draft Model +398% on H200. The regression cannot be explained by batch-size saturation. H200/H100 baseline is so fast (5–7ms/token) that any fixed overhead per spec step is a large fraction of the target decode time. This is the "fast GPU, bad for spec decode" trap: the smaller the baseline latency, the harder it is to recoup the verification cost.
Q3: What acceptance rates did we observe, and what do they imply?
Observed vs expected acceptance rates (H200, k=5, ShareGPT):
- N-gram: 48.62% observed (expected 45–55%) — matches expectation. N-gram on ShareGPT is fundamentally limited by the low text repetition in conversation data.
- Draft Model (Llama-3.2-1B): 52.49% observed (expected 50–65%) — within range. Acceptance length 3.62 means on average 3.6 tokens are produced per spec step, but the draft forward passes cost too much on H200's fast baseline.
- EAGLE: 21.56% observed (expected 85–95%) — catastrophically below expectation. Per-position: 57% → 28% → 13% → 6% → 3%. Liu et al. report position-0 acceptance of ~92% on vLLM v0.10.1.1; we observe 57%. The 35-percentage-point gap at position 0 alone suggests the EAGLE model is producing systematically wrong proposals — consistent with a version mismatch between the EAGLE head weights and vLLM v0.19.0's hidden-state API.
Practical implication: For spec decode to provide net benefit on H200/H100 running 8B models, you would need: (a) EAGLE with correctly matched weights yielding ~85% acceptance, AND (b) a smaller k (e.g., k=2 or k=3) to limit verification overhead. Alternatively, move to a 70B+ model where baseline ITL is >20ms/token and the verification cost is a smaller fraction of the gain.