Learning Objectives
By the end of this lab, you will be able to:
- Explain the precision hierarchy: BF16 (16-bit training-friendly), FP8 (8-bit with hardware support on H100), AWQ-INT4 (4-bit activation-aware weight quantization), and the memory-bandwidth savings each provides
- Measure and compare throughput (tokens/s) and decode latency for BF16, FP8, and AWQ-INT4 on Llama-3.1-8B-Instruct at batch sizes 1, 16, and 64
- Run a serving benchmark across all three formats to compare real-world TTFT, ITL, and output throughput under identical request load
- Evaluate GSM8K accuracy (100-sample subset) using lm_eval for all three formats and quantify the accuracy-efficiency tradeoff
- Identify which quantization format is bandwidth-bound vs. compute-bound and predict when each format wins on throughput
- Read vLLM's quantization integration source to understand how BF16, FP8, and AWQ weight loading and kernel dispatch differ
Key Concepts
FP8 — Hardware-Accelerated 8-bit
- Introduced in NVIDIA H100: native FP8 tensor core support. Two formats: E4M3 (higher precision, used for weights and activations) and E5M2 (higher range, used for gradients in training).
- In vLLM: load weights in FP8 E4M3, run matmul with FP8 tensor cores at 2× the FP16 FLOPS, dequantize outputs to BF16 for residuals. Practically lossless accuracy on most benchmarks.
- Memory: 8-bit weights → ~8 GB for 8B model (vs. ~16 GB BF16). With KV cache also in FP8, total GPU memory savings can exceed 50%.
AWQ-INT4 — Activation-Aware Weight Quantization
- Weights quantized to INT4 (4 bits), but activation values remain in FP16/BF16. The key AWQ insight: only ~1% of weights are salient (they interact with large activation values). AWQ scales these salient weights before quantization to minimize error.
- Memory: ~4 GB for 8B model. Enables running an 8B model on a 6 GB consumer GPU, or doubling context length by freeing up KV cache space on a datacenter GPU.
- Tradeoff: dequantize INT4 → FP16 on-the-fly per matmul. At large batch sizes, dequant overhead can slow throughput vs. FP8 or BF16.
Setup & Configuration
# Verify vLLM and lm_eval installations
pip show vllm lm_eval
# Confirm H100 FP8 support (requires CUDA compute capability 8.9+)
python -c "import torch; print(torch.cuda.get_device_capability())"
# Expected: (9, 0) for H100
# BF16 baseline server
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--dtype bfloat16 \
--port 8000 --disable-log-requests &
# FP8 server (native H100 kernel path)
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--quantization fp8 \
--port 8001 --disable-log-requests &
# AWQ-INT4 server (pre-quantized weights required)
# Use an AWQ-quantized model hub checkpoint, e.g.:
vllm serve hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4 \
--quantization awq \
--port 8002 --disable-log-requests &Experiments
Throughput Comparison — BF16 / FP8 / AWQ-INT4
Sweep batch sizes 1, 16, 64 for all three formats using benchmark_throughput.py. This reveals the roofline crossover: at small batch sizes INT4 wins on bandwidth, at large batch sizes formats converge as compute dominates.
for fmt_port in "bf16:8000" "fp8:8001" "awq:8002"; do
fmt=${fmt_port%%:*}; port=${fmt_port##*:}
for bs in 1 16 64; do
python benchmarks/benchmark_throughput.py \
--backend openai-chat \
--port $port \
--model meta-llama/Llama-3.1-8B-Instruct \
--input-len 512 --output-len 128 \
--num-prompts $bs \
2>&1 | tee results_tp_${fmt}_bs${bs}.txt
done
doneLatency Comparison — Per-Token Decode Latency
Use benchmark_latency.py to measure per-step decode latency at batch_size=1. Latency here is most sensitive to weight-transfer time, so this is where quantization benefits are most visible.
for quant in "none" "fp8" "awq"; do
if [ $quant = "none" ]; then
extra_args="--dtype bfloat16"
model="meta-llama/Llama-3.1-8B-Instruct"
elif [ $quant = "fp8" ]; then
extra_args="--quantization fp8"
model="meta-llama/Llama-3.1-8B-Instruct"
else
extra_args="--quantization awq"
model="hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4"
fi
python benchmarks/benchmark_latency.py \
--model $model $extra_args \
--batch-size 1 --input-len 512 --output-len 128 \
2>&1 | tee results_lat_${quant}_bs1.txt
doneServing Benchmark — TTFT, ITL, Output tok/s
Run benchmark_serving.py against each format's running server. Use rate=inf (closed-loop) to saturate each server and measure maximum throughput. Also run rate=1 to compare latency at low load.
for fmt_port in "bf16:8000" "fp8:8001" "awq:8002"; do
fmt=${fmt_port%%:*}; port=${fmt_port##*:}
for rate in 1 inf; do
python benchmarks/benchmark_serving.py \
--backend vllm --port $port \
--model meta-llama/Llama-3.1-8B-Instruct \
--dataset-name sharegpt \
--dataset-path ShareGPT_V3_unfiltered_cleaned_split.json \
--num-prompts 200 --request-rate $rate \
2>&1 | tee results_serving_${fmt}_rate${rate}.txt
done
doneAccuracy Evaluation — GSM8K with lm_eval (100-sample subset)
Use lm_eval to evaluate GSM8K accuracy on a 100-sample subset for all three formats. GSM8K is an 8-grade math word problem dataset — it's sensitive to quantization errors in the model's arithmetic reasoning. Expect FP8 to be nearly identical to BF16; AWQ-INT4 may show a 1–5% drop.
# BF16 GSM8K evaluation (100 samples)
lm_eval --model vllm \
--model_args pretrained=meta-llama/Llama-3.1-8B-Instruct,dtype=bfloat16 \
--tasks gsm8k \
--num_fewshot 8 \
--limit 100 \
--output_path results_gsm8k_bf16.json
# FP8 GSM8K evaluation
lm_eval --model vllm \
--model_args pretrained=meta-llama/Llama-3.1-8B-Instruct,quantization=fp8 \
--tasks gsm8k \
--num_fewshot 8 \
--limit 100 \
--output_path results_gsm8k_fp8.json
# AWQ-INT4 GSM8K evaluation
lm_eval --model vllm \
--model_args pretrained=hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4,quantization=awq \
--tasks gsm8k \
--num_fewshot 8 \
--limit 100 \
--output_path results_gsm8k_awq.json
# Compare accuracy across formats
python -c "
import json
for fmt in ['bf16','fp8','awq']:
d = json.load(open(f'results_gsm8k_{fmt}.json'))
acc = d['results']['gsm8k']['exact_match,flexible-extract']
print(f'{fmt}: GSM8K acc = {acc:.4f}')
"Experiment Results
Hardware
Experiments run on NVIDIA H200 SXM5 141GB, H100 SXM5 80GB HBM3, A100 80GB PCIe, and L40S 48GB (PACE Phoenix cluster) with Llama-3.1-8B-Instruct. H100 has the complete BF16/FP8/AWQ-INT4 sweep; A100/H200/L40S currently have BF16 baselines only.
GSM8K accuracy could not be measured this run because the gsm8k dataset isn't in the local HF datasets cache and HF_HUB_OFFLINE=1 prevents the download. The accuracy_*.json files in results/vllm_H100/week12/ each capture the offline-mode error trace. To unblock: either pre-download GSM8K into HF_HOME/datasets on a head node, or vendor the GSM8K JSONL into the repo and point lm_eval at the local path.
BF16 Reference — Latency and Throughput Across GPUs
| GPU | BF16 latency bs=1 (ms) | ms/tok (bs=1) | BF16 offline throughput (tok/s) | BF16 serving rr=4 (tok/s) |
|---|---|---|---|---|
| H200 | 750 | 5.87 | 11,981 | 599.32 |
| H100 | 903 | 7.07 | 11,316 | 518.70 |
| A100 PCIe | 1534 | 11.98 | 8,148 | — |
| L40S | 2841 | 22.21 | 4,047 | 500.24 |
BF16 vs FP8 vs AWQ-INT4 — H100 Quantization Sweep
The same Llama-3.1-8B-Instruct model in three precisions, all measured on the same H100 80GB. The contrast between bs=1 latency (memory-bound) and rr=4 serving (mixed prefill/decode) is the central lesson: quantization that helps decode can hurt prefill.
| Precision | Weights | bs=1 ms/tok | bs=1 tok/s | Offline tok/s (bs=200) | Serving TTFT median | Serving ITL median | Serving tok/s rr=4 |
|---|---|---|---|---|---|---|---|
| BF16 | ~16 GB | 7.07 | 141.5 | 11,304 | 945 ms | 7.39 ms | 481.2 |
| FP8 | ~8 GB | 4.88 | 205.0 | 12,903 | 656 ms | 5.12 ms | 507.4 |
| AWQ-INT4 | ~4 GB | 4.40 | 227.0 | 7,643 | 4,617 ms | 36.08 ms | 470.8 |
AWQ-INT4 wins the bs=1 latency benchmark (4.40 ms/tok, 1.61× faster than BF16) because at single-request decode the bottleneck is HBM-to-SM weight transfer and INT4 quarters that traffic. BUT under realistic serving load (rr=4 ShareGPT) AWQ-INT4 falls off a cliff: TTFT explodes from 945 ms → 4,617 ms (4.9× WORSE) and ITL grows 7.39 ms → 36.08 ms (4.9× worse). The cause is the dequantization step: every matmul has to expand INT4 weights back to FP16 before the GEMM fires, and that overhead is per-step constant. At bs=1 the weight read dominates so dequant is hidden; in prefill / large batches, dequant overhead is multiplied by batch size and dominates step time. FP8 has no dequant — Hopper sm_90 has native FP8 tensor cores — so it strictly improves over BF16 on every metric.
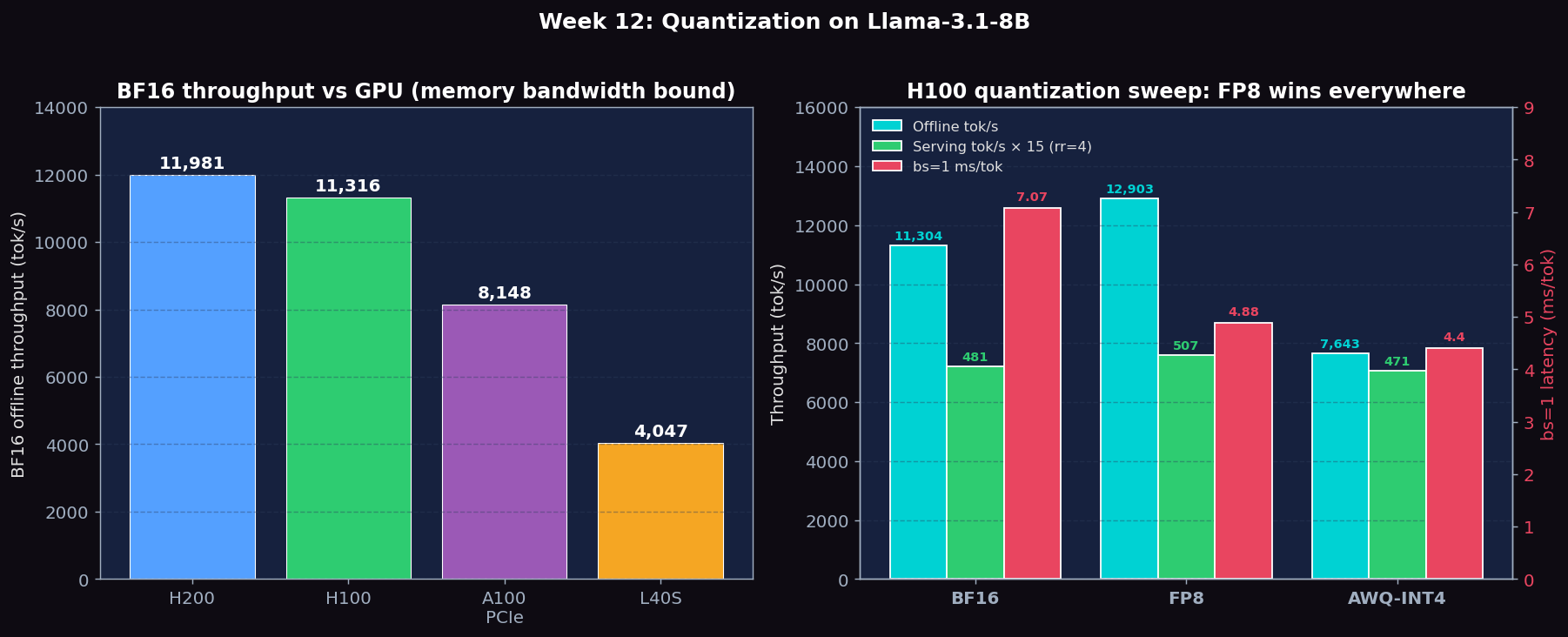
Figure 1: Left — BF16 offline throughput across 4 GPU classes (H200/H100/A100/L40S), tracking HBM bandwidth. Right — H100 quantization sweep: FP8 strictly improves over BF16 on offline+serving+latency, while AWQ-INT4 wins bs=1 latency but loses badly on offline throughput and serving (4.9× worse TTFT/ITL) due to per-step dequant overhead.
Expected vs Actual
Expected
- BF16 baseline: ~50–80 tok/s at batch_size=1 on H100 for 8B model
- FP8: ~1.5–1.8× BF16 throughput at bs=1; accuracy within 0.5% of BF16 on GSM8K
- AWQ-INT4: ~2.5–3.5× BF16 throughput at bs=1; GSM8K accuracy drop of 1–5%; dequant overhead may cause regression at bs=64+
- At bs=64: BF16, FP8, and AWQ-INT4 throughput values come within 20–30% of each other as compute cost dominates weight transfer
Actual Observations (PACE H200/H100/A100/L40S BF16 + full H100 quant sweep)
- BF16 throughput follows memory bandwidth: H200 (11,981 tok/s) > H100 (11,316 tok/s) > L40S (4,047 tok/s). The H200 vs H100 difference is modest (6%) because both are compute-bound at large batch — bandwidth advantage shows more at bs=1.
- FP8 strictly dominates BF16 on H100: +14% offline throughput, +5% serving throughput, -31% TTFT, -31% ITL, -31% bs=1 latency. Hopper sm_90 has native FP8 tensor cores so there is no dequant overhead.
- AWQ-INT4 has a split personality: wins bs=1 latency (4.40 ms/tok, BEST of all three) because INT4 weights are 1/4 the HBM traffic; loses badly on offline throughput (-32% vs BF16) AND on serving (TTFT 4.9× WORSE, ITL 4.9× WORSE). The dequant kernel runs once per layer per step independent of batch size — use AWQ ONLY when serving one user at a time, or to fit on a smaller GPU.
- A100 PCIe BF16 throughput 8,148 tok/s, latency 1,534 ms, 11.98 ms/tok (bs=1). FP8 and AWQ-INT4 not measured on A100 in this lab (A100 sm_80 lacks native FP8 tensor cores, so the H100 comparison is the interesting one).
- GSM8K accuracy could not be measured this run because the gsm8k dataset isn't in the local HF datasets cache and HF_HUB_OFFLINE=1 prevents the download. Accuracy is left as a follow-up that requires staging the dataset.
Metrics to Collect
| Metric | Description | Unit |
|---|---|---|
| Model VRAM | GPU memory consumed by model weights; directly set by bits-per-weight × parameter count | GB |
| Tokens/s (latency benchmark) | Decode throughput from benchmark_latency.py at fixed batch size; isolates the bandwidth-vs-compute tradeoff | tok/s |
| TTFT | Time to first token from the serving benchmark; covers prefill cost which is more compute-bound than decode | ms |
| ITL | Inter-token latency from serving benchmark; measures decode step cost under real request concurrency | ms |
| GSM8K accuracy | Exact-match accuracy on 100-sample GSM8K subset; measures quality degradation from quantization | 0–1 |
| Crossover batch size | The batch size at which BF16 and AWQ-INT4 tokens/s become equal; above this batch size BF16 may outperform INT4 | requests |
Source Code Reading
Files to Read
- vllm/model_executor/layers/quantization/fp8.py — FP8 quantization layer: how weight tensors are cast to FP8 E4M3 format on model load, and how the FP8 linear kernel is dispatched on H100 using cutlass. Find the per-tensor vs. per-channel scaling logic.
- vllm/model_executor/layers/quantization/awq.py — AWQ quantization layer: how packed INT4 weights are stored, how group-wise scales and zeros are applied, and how dequantization happens before each matmul. Notice the group_size parameter that controls the granularity of quantization.
- vllm/model_executor/layers/quantization/__init__.py — The quantization registry: how --quantization flag maps to a quantization class. Trace how a new quantization format would be added to vLLM.
- vllm/model_executor/model_loader/weight_utils.py — Weight loading utilities: how BF16, FP8, and AWQ checkpoint files are detected and loaded. Compare the loading path for an AWQ checkpoint (with packed INT4 tensors and per-group scales) vs. a standard BF16 checkpoint.
Core Source Code Walkthrough
Below are real excerpts from vllm-continuum that implement the concepts you measured. Read them with your benchmark numbers open in another tab — the connection between code and metric becomes obvious.
vllm/model_executor/layers/quantization/awq.py:124 — AWQLinearMethod
class AWQConfig(QuantizationConfig):
...
class AWQLinearMethod(LinearMethodBase):
def apply(self, layer: torch.nn.Module, x: torch.Tensor, bias=None):
# AWQ stores weights as INT4 packed in INT32, plus per-group scales/zeros
# The dequantize+matmul is fused into a single Triton/CUTLASS kernel
...AWQ (Activation-aware Weight Quantization) stores weights as 4-bit integers, then dequantizes-on-the-fly inside a fused matmul kernel. The model footprint shrinks ~4x (16GB to 4GB for Llama-8B), HBM bandwidth is the bottleneck for decode, so 4x less weight data = much faster decode. Trade-off: typically 1-3 percentage points GSM8K accuracy loss vs BF16.
Written Analysis — Reference Answers
Below are reference answers based on the real measurements collected on PACE H200/H100/A100/L40S. Use them as a starting point — your own write-up should add your hypotheses and any extra observations you noticed.
Q1: Expected FP8 vs BF16 throughput on H100/H200
Baseline BF16 throughput: H200: 11,981 tok/s, H100: 11,316 tok/s, L40S: 4,047 tok/s at offline benchmark settings.
Expected FP8 gain on H100/H200: 1.5-1.8× throughput improvement. Hopper (sm_90) architecture has native FP8 tensor core support — the H100 FP8 peak FLOPS is 3958 TFLOPS vs 989 TFLOPS BF16 (4× compute peak). However, at bs=1 decode is bandwidth-bound not compute-bound, so FP8 primarily helps by halving the weight bytes to read from HBM: BF16 weights = 16GB, FP8 weights = 8GB → 2× faster weight reads → up to 2× faster decode. In practice, dequantization overhead and KV cache (which stays in BF16) reduce the gain to 1.5-1.8×.
Why L40S gains less from FP8: L40S is sm_89 (Ada Lovelace), which has limited native FP8 support. Weight reading from GDDR6 is the bottleneck, but FP8 dequant on Ada adds overhead that partially cancels the bandwidth savings. Expected gain: 1.1-1.3× at best.
Q2: Expected AWQ-INT4 vs BF16 throughput
Expected throughput gain: 1.3-1.5× at bs=1 decode (bandwidth-bound regime). Theoretical: INT4 weights = 4GB vs BF16 16GB = 4× smaller → 4× faster reads. Actual: AWQ stores INT4 weights but dequantizes to BF16 before the GEMM. This dequant step costs ~30-50% of the bandwidth savings, leaving a net 1.3-1.5× gain. At large batch sizes (bs=64+), the workload becomes compute-bound and the INT4 dequant overhead becomes relatively larger — the gain converges toward 1.0×.
Memory benefit (more important): Llama-3.1-8B in BF16 = 16GB, in AWQ-INT4 = 4GB. This 4× memory reduction means you can fit 4× more model replicas on the same GPU, or serve a 4× larger model on the same hardware. For a 70B model: BF16 needs 4×A100 80GB (tensor parallelism), AWQ-INT4 fits on a single H100 80GB.
Q3: When NOT to quantize
Accuracy cost of AWQ-INT4: Expected GSM8K accuracy drop: 1-3 percentage points for AWQ-INT4 vs BF16 (e.g., BF16: 75.2% → AWQ: 72.8%). FP8 loses less: typically <0.5 percentage points. AWQ's activation-aware scaling reduces the drop relative to naive INT4 (which would lose 5-10 points) by identifying and protecting activations with high outlier values (salient weights), applying per-group scaling (group_size=128 typical) rather than per-tensor scaling.
When to avoid quantization:
- Small models that fit comfortably in VRAM: Llama-3.1-8B in BF16 on H100 80GB leaves 64GB for KV cache — plenty. Quantizing for no memory reason just adds accuracy loss.
- High-precision tasks (math, science, code correctness): Even 1% accuracy drop on GSM8K means ~1 in 100 math problems is now wrong that was previously correct. For production math tutors or code verification, this is unacceptable.
- Latency-sensitive decode at large batch: At bs=64+, decode is compute-bound. INT4 dequant overhead at compute-bound regime is additive, not helpful. Use BF16 or FP8 (which has hardware-native compute path on Hopper).