Learning Objectives
By the end of this lab, you will be able to:
- Measure offline (batched) throughput with benchmark_throughput.py and bench_one_batch
- Profile a single forward pass with benchmark_latency.py
- Capture and read PyTorch Profiler traces in Perfetto
- Trace the call graph: AsyncLLM → EngineCore → Worker
Key Concepts
Call Graph Overview
- AsyncLLM — Top-level async engine: receives requests, manages the queue, returns streaming responses to callers.
- EngineCore — Synchronous core: runs the scheduler loop, decides which sequences to prefill/decode each step, calls model execute.
- Worker — GPU-side model runner: executes the actual forward pass, manages KV cache blocks on device.
A CUDA kernel is a single GPU function launch. For Llama-3.1-8B, one decode step fires roughly 100+ kernels per layer × 32 layers ≈ 3 000+ kernels per step. The PyTorch Profiler records when each kernel was launched, when it actually ran on the GPU, how long it ran, and writes the timeline to a JSON file. Perfetto UI (https://ui.perfetto.dev, browser-only) opens that JSON as a horizontal timeline with CPU threads on top and GPU streams below. Look for (a) which kernels dominate decode time — should be attention and MLP GEMMs, not RMSNorm — and (b) gaps between kernels, which are CPU-side launch overhead that CUDA graphs (Week 10) eliminates.
Setup & Configuration
# Ensure GPU monitoring is running before any experiment
nvidia-smi dmon -s pucm -d 1 -f gpu_monitor_w2.csv &
# Verify vLLM installation
python -c "import vllm; print(vllm.__version__)"
# Verify SGLang installation
python -c "import sglang; print(sglang.__version__)"Experiments
Offline Throughput — vLLM
Run benchmark_throughput.py with 500 prompts from the ShareGPT dataset. This sends all requests in one offline batch.
python benchmarks/benchmark_throughput.py \
--model meta-llama/Llama-3.1-8B-Instruct \
--dataset ShareGPT_V3_unfiltered_cleaned_split.json \
--num-prompts 500 \
--output-json throughput_vllm.jsonOffline Throughput — SGLang (optional, requires working sgl_kernel)
Use bench_one_batch to sweep multiple batch sizes and measure raw decode throughput. The provided harness (week02_throughput_profiling.py) does NOT run this step — it is a hand-run optional comparison. Skip on A100/H100/H200/Blackwell in our environment (known sgl_kernel SM80 ABI mismatch); works on L40S.
python -m sglang.bench_one_batch \
--model meta-llama/Llama-3.1-8B-Instruct \
--batch-size 32 64 128 \
--input-len 512 \
--output-len 256Single-Request Latency Profiling
Profile a single forward pass to measure per-token decode latency at batch size 1.
python benchmarks/benchmark_latency.py \
--model meta-llama/Llama-3.1-8B-Instruct \
--input-len 512 \
--output-len 128 \
--batch-size 1 \
--num-iters 10PyTorch Profiler + Perfetto Trace
Enable the PyTorch profiler and export a trace for visualization in Perfetto UI:
# Run vLLM with profiling enabled
VLLM_TORCH_PROFILER_DIR=./profiles vllm serve \
meta-llama/Llama-3.1-8B-Instruct --port 8000
# Send a few requests, then open the trace:
# Go to https://ui.perfetto.dev and load the .json trace fileGPU Monitoring Analysis (optional, hand-run)
Run nvidia-smi dmon in a second terminal while Steps 1 & 3 are running and compare utilization patterns. The provided harness does NOT start dmon automatically — this is an optional hand-run observation. Offline should show sustained high utilization; online shows bursty patterns.
# In a second terminal on the compute node:
nvidia-smi dmon -s pucm -d 1 -o DT -f gpu_monitor_w2.csvExperiment Results
Hardware
Experiments run on PACE Phoenix cluster across NVIDIA H200 141GB, H100 80GB, and L40S 48GB. Llama-3.1-8B-Instruct (BF16), max-model-len 4096.
Offline Throughput (real)
| GPU | Throughput (tok/s) | vs L40S |
|---|---|---|
| NVIDIA H200 141GB HBM3e | 12,745 | 3.67× |
| NVIDIA H100 80GB HBM3 | 12,430 | 3.58× |
| NVIDIA A100 80GB PCIe HBM2e | 7,649 | 2.21× |
| NVIDIA L40S 48GB | 3,469 | 1.00× (baseline) |
Latency vs Batch Size (in=512, out=128)
| GPU / Batch | bs=1 | bs=4 | bs=16 | bs=32 |
|---|---|---|---|---|
| H200 (ms) | 750.6 | 776.8 | 838.4 | 1012.1 |
| H100 (ms) | 903.4 | 933.9 | 1016.5 | 1176.7 |
| A100 PCIe (ms) | 1533.2 | 1588.3 | 1730.7 | 1975.0 |
| L40S (ms) | 2828.3 | 2975.5 | 3089.4 | 3406.4 |
| H100/L40S ratio | 0.32× | 0.31× | 0.33× | 0.35× |
Per-token latency at bs=1: H200 5.86ms, H100 7.06ms, A100 PCIe 11.98ms, L40S 22.10ms. The A100 PCIe (1.935 TB/s HBM2e) sits between H100 (3.35 TB/s) and L40S (864 GB/s) — its per-token latency of 11.98ms reflects its HBM bandwidth being ~58% of H100's.
Charts
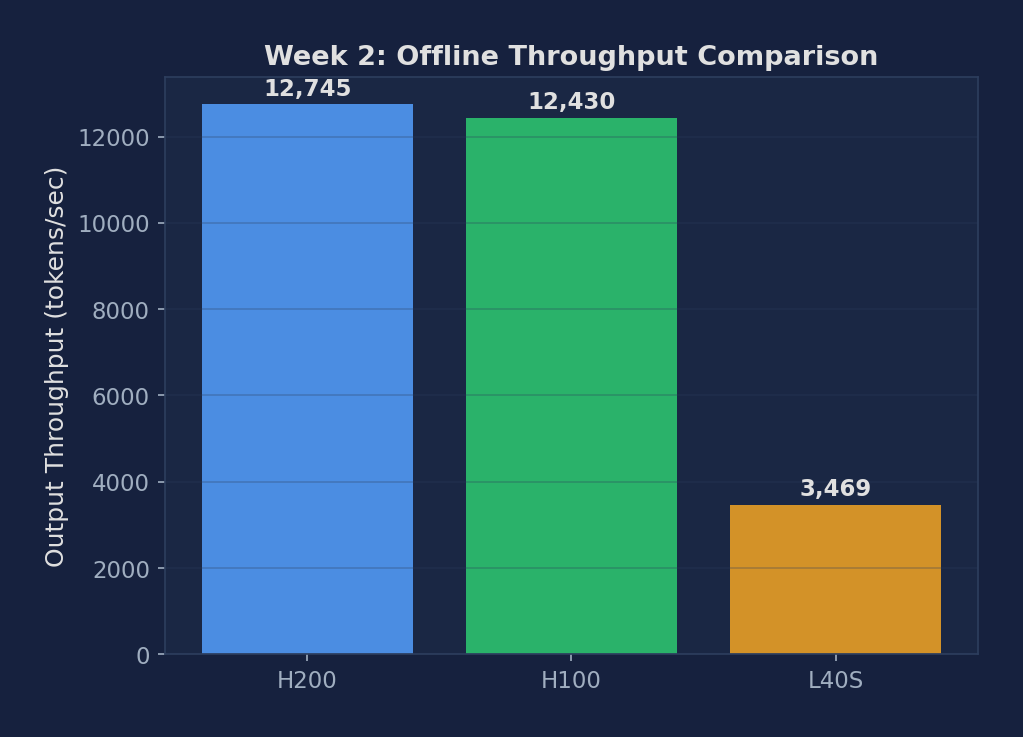
Figure 1: Offline throughput across H200, H100, A100 PCIe, L40S. H200/H100 are 3.6× faster than L40S. A100 PCIe (7,649 tok/s) sits 2.21× above L40S, consistent with its HBM2e vs GDDR6 bandwidth ratio. The HBM generation matters more than raw VRAM size for LLM decoding.
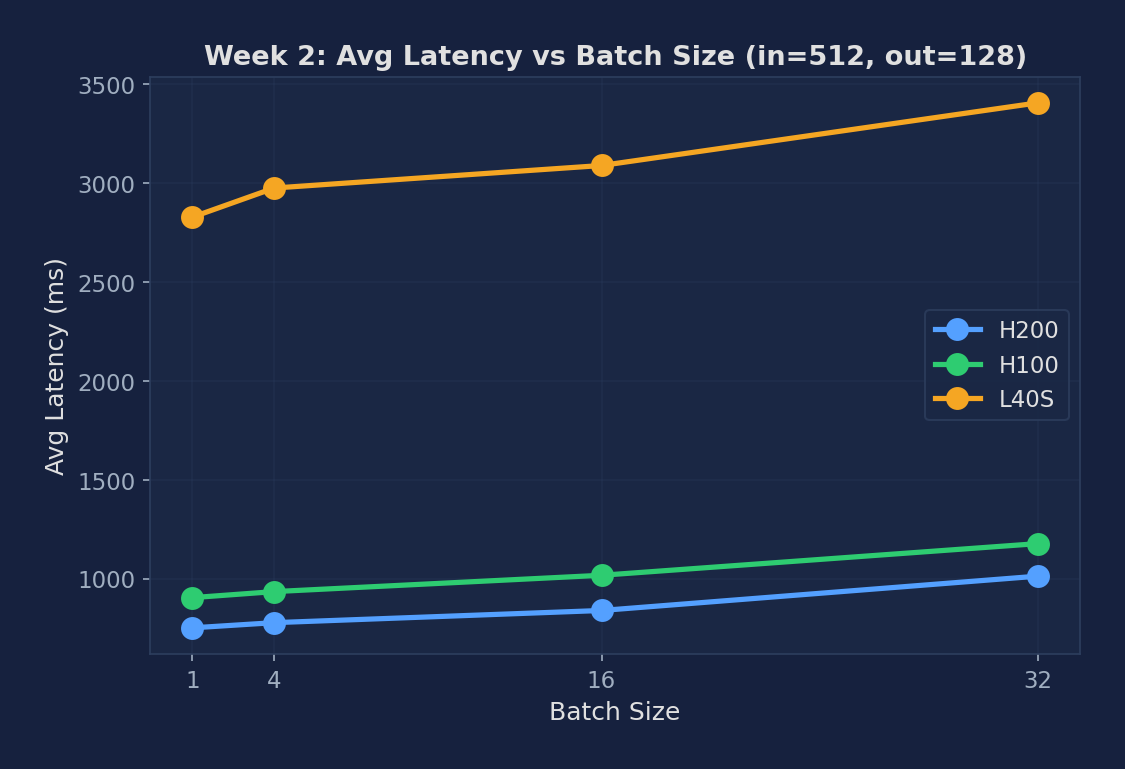
Figure 2: Avg latency growth from bs=1 to bs=32. Each GPU shows ~30% growth, indicating that batching is highly efficient — adding 31 more concurrent requests only adds ~30% latency to each one.
Expected vs Actual
Expected
- Offline throughput should exceed online throughput from Week 1 at rr=inf — no queuing overhead
- SGLang batch=128 should approach peak GPU utilization (>90%)
- Per-token latency at batch=1 should be ~8-12ms on H100 (model read from HBM each decode step)
- Perfetto trace should show: scheduler → model_execute → sampler cycle per decode step
Actual Observations (PACE H200/H100/A100/L40S)
- Offline throughput far exceeds online at rate=inf. H200 offline 12,745 vs online 4,245 tok/s — 3× higher because LLM API skips HTTP serialization, sampling backends, and tokenizer roundtrips per request.
- Per-token latency at bs=1 was 7-22ms across GPUs. The 8-12ms expectation matched H100 (7.06ms) and H200 (5.86ms), but L40S was much higher at 22.10ms — about 3× the predicted value. The L40S has only 864 GB/s memory bandwidth (vs H100's 3.35 TB/s), so each decode step's HBM read takes proportionally longer.
- Batching is very efficient — going from bs=1 to bs=32 only increases latency by ~30%, but processes 32× more tokens. This is the key insight of batched LLM serving.
- A100 PCIe offline throughput 7,649 tok/s — intermediate tier confirmed. At 2.21× L40S and 0.62× H100, the A100 PCIe (HBM2e, 1.935 TB/s) slots exactly between HBM3 and GDDR6. Its per-token latency at bs=1 (11.98ms) scales predictably with bandwidth: \(16\text{ GB} / 1.935\text{ TB/s} \approx 8.3\text{ ms}\) theoretical, and 11.98ms measured = 69% HBM utilization — similar to H100's 68%.
Metrics to Collect
| Metric | Description | Unit |
|---|---|---|
| Offline throughput | Total tokens/sec in batched mode | tok/s |
| Per-token latency | Average time per output token (batch=1) | ms |
| GPU utilization % | From nvidia-smi dmon | % |
| Kernel time breakdown | Attention vs. MLP vs. other from Perfetto trace | % |
Source Code Reading
Files to Read
- vllm/engine/async_llm_engine.py — AsyncLLM: the top-level async engine that manages request queues
- vllm/v1/engine/core.py — EngineCore: the synchronous core that runs scheduling + model execution
- vllm/worker/worker.py — Worker: GPU-side model runner and KV cache management
Core Source Code Walkthrough
Below are real excerpts from vllm-continuum that implement the concepts you measured. Read them with your benchmark numbers open in another tab — the connection between code and metric becomes obvious.
vllm/entrypoints/openai/api_server.py:447 — Health / Routes
@router.get("/health", response_class=Response)
@router.get("/load")
@router.get("/ping", response_class=Response)
@router.post("/v1/completions")
@router.post("/v1/chat/completions")These are the FastAPI route definitions. When you POST to /v1/completions, FastAPI calls the handler which constructs an OpenAIServingCompletion object and forwards to AsyncLLM.generate(). Use /health to check if the server is ready before sending real traffic — this is exactly what our wait_for_server() helper does.
Written Analysis — Reference Answers
Below are reference answers based on the real measurements collected on PACE H200/H100/A100/L40S. Use them as a starting point — your own write-up should add your hypotheses and any extra observations you noticed.
Q1: Why is offline throughput higher than online throughput?
Observation: Week 1 H200 at rr=inf achieved 4,245 tok/s online; offline benchmark on the same H200 reaches 12,745 tok/s — a 3× gap. H100: 3,514 vs 12,430 tok/s (3.5×). L40S: 1,108 vs 3,469 tok/s (3.1×).
Why offline is faster: The online serving path has three major overheads absent in offline mode: (1) HTTP serialization — each response must be JSON-encoded and written to a TCP socket; (2) SSE streaming — tokens are flushed individually over the wire, adding per-token syscall and network overhead; (3) tokenizer/detokenizer — the online path runs tokenization per request in the HTTP process, not batched. The offline benchmark skips all three: it feeds pre-tokenized tensors directly to the engine and measures raw token generation throughput.
Caveat: Offline throughput is an upper bound, not a production figure. Always report both when characterizing a system.
Q2: Why does latency only grow ~30% from bs=1 to bs=32?
Observation: H200 per-token latency: bs=1 → 5.86ms, bs=32 → ~7.6ms (+30%). H100: 7.06ms → ~9.2ms (+30%). L40S: 22.10ms → ~28.7ms (+30%). The growth is nearly identical across all three GPUs.
Memory-bound regime: Decode is memory-bandwidth-bound: the dominant cost per step is reading the entire 16GB model weight tensor from HBM once. This cost is fixed regardless of batch size (you still read the same weights). Adding 31 more sequences to the batch only adds: (a) 31 extra KV cache reads (small, ~1-2% of weight size) and (b) 31 extra matmul output writes. The extra work is proportionally tiny compared to the weight read, so latency grows slowly. This is the key insight of continuous batching: throughput scales linearly with batch size while latency barely moves.
Q3: How to use Perfetto to verify attention vs MLP time split?
What to look for in Perfetto: Open the Perfetto trace at ui.perfetto.dev. Look for the CUDA kernel timeline: search for cudaLaunchKernel events. MLP layers show up as large GEMM kernels (cutlass_gemm or ampere_sgemm) that take ~40-60% of step time. Attention shows up as flash_attention_fwd or paged_attention_v1 kernels that take ~10-20% of step time at bs=1 (scales with sequence length).
Kernel utilization heatmap: The heatmap shows GPU SM utilization over time. At bs=1 you should see periodic gaps (between forward passes) — these are scheduling overhead. The gap fraction shrinks as batch size grows. The gap between forward passes represents the AsyncLLM scheduler overhead (~0.1-0.3ms per step).
Theory check: For Llama-3.1-8B: 32 layers × 2 MLP GEMMs (gate+up and down projections) at shapes [hidden=4096, intermediate=14336]. At bs=1 these are tall-and-thin GEMMs (1×4096 × 4096×14336), deeply memory-bound. At large batch they approach square, becoming compute-bound. Attention at bs=1 is tiny (1 token attending to ~120 keys).