1. Experiment Setup
1.1 Hardware
| GPU | VRAM | KV Cache Tokens (16k ctx) | Partition |
|---|---|---|---|
| H100 80GB HBM3 | 80 GB | ~458K | PACE gpu-h100 |
| A100 PCIE 40GB (mixed in partition) | 40 GB | ~90K | PACE gpu-a100 |
| A100 PCIE 80GB (mixed in partition) | 80 GB | ~200K | PACE gpu-a100 |
| H200 141GB HBM3e | 141 GB | ~825K | PACE gpu-h200 |
1.2 Model & dataset
| Field | Value |
|---|---|
| Model | meta-llama/Llama-3.1-8B-Instruct (14.99 GB, bfloat16) |
| Dataset | princeton-nlp/SWE-smith-trajectories — 100 curated trajectories, mean 17.9 turns/job, median 6945 input / 30 output tokens per turn (highly prefix-cache-friendly) |
Tool distribution
| Tool | Share | Tool | Share |
|---|---|---|---|
cd | 26% | submit | 11% |
editor_view | 21% | find | 6% |
editor_create | 13% | rm | 5% |
editor_str_replace | 12% | grep | 4% |
| others | 2% | ||
Each SWE-smith trajectory is an OpenAI-format chat log: a system prompt, the issue description as the user message, and alternating assistant / tool turns. A worked example showing the JSON structure together with its per-turn token budget lives in §2.1.
1.3 Scheduling policies tested
| Policy variant | KV strategy | External tier |
|---|---|---|
fcfs | V1 FCFS admission | — |
continuum | Pin held-KV for 2 s TTL if estimated tool-exec ≤ threshold | — |
cpu_offload_dram16 | SimpleCPUOffloadConnector | 16 GB DRAM |
cpu_offload_dram128 | SimpleCPUOffloadConnector | 128 GB DRAM |
lmcache_dram16 | LMCacheConnectorV1 | 16 GB DRAM |
lmcache_dram128 | LMCacheConnectorV1 | 128 GB DRAM |
1.4 Arrival rate sweep
Jobs arrive as a Poisson process. JPS (jobs per second) values: 1, 3, 6, 10. Each job runs its full ~18-turn trajectory; between turns a 1-second synthesized tool-exec delay is inserted to emulate real agent loop back-pressure.
2. Per-turn prefill / decode token budget
Every chat turn of a job goes through exactly two phases inside the vLLM engine:
- Prefill — one forward pass over the input tokens that are not already in the prefix cache. Counts as ≥ 1 step (1 if all uncached tokens fit in
max_num_batched_tokens, otherwise split into chunked-prefill steps). - Decode — each forward pass emits exactly one token. N output tokens ⇒ N decode steps.
Minimum engine steps for a single turn = 1 (prefill, ≥ 1 if chunked) + N (one per decoded token) = 1 + num_output_tokens.
2.1 Worked example — astropy__astropy-12907 turn 2
The trajectory (abridged) and the token accounting for turn 2 share one block below. Counts are representative (Llama-3.1 tokenizer).
# ── Trajectory (abridged, 2 of ~17 turns shown) ──────────────────────────
{
"instance_id": "astropy__astropy-12907",
"messages": [
{"role": "system",
"content": "You are a SWE agent. Use the tools to explore the repo and fix the issue…"},
{"role": "user",
"content": "<issue>Modeling's `separability_matrix` does not compute separability correctly for nested CompoundModels</issue><repo>astropy/astropy</repo>"},
// turn 1 — explore
{"role": "assistant",
"content": "Let me look at the modeling package.",
"tool_calls": [{"id": "c1", "type": "function",
"function": {"name": "cd", "arguments": "{\"path\": \"astropy/modeling\"}"}}]},
{"role": "tool", "tool_call_id": "c1", "content": "/astropy/modeling"},
// turn 2 — read the suspect file ← the turn we score below
{"role": "assistant",
"content": "Opening separable.py to inspect _separable().",
"tool_calls": [{"id": "c2", "type": "function",
"function": {"name": "editor_view", "arguments": "{\"path\": \"separable.py\", \"view_range\": [1, 120]}"}}]},
{"role": "tool", "tool_call_id": "c2",
"content": "def _separable(transform): … # ~115 lines of source"},
// … 15 more turns (editor_str_replace, editor_view, editor_str_replace, submit) …
]
}
# ── Turn 2 · Input side — prompt_tokens fed to the engine ────────────────
system prompt … 604 tok
user (issue body + reproduction code) … 1,498 tok
turn 1 assistant text + tool_calls JSON … 35 tok
turn 1 synthesized ```bash cd ``` … 5 tok
turn 1 tool response "/astropy/modeling" … 10 tok
turn 2 assistant role prefix … 3 tok
─────────
prompt_tokens (prefill input) = 2,155 tok
# ── Turn 2 · Output side — tokens generated during decode ────────────────
"Opening separable.py to inspect _separable()." → 10 tok
tool_calls JSON (editor_view, separable.py, 1..120) → 13 tok
synthesized ```bash\neditor_view\n``` → 5 tok
─────────
output_tokens = 28 tok
# ── Turn 2 · Minimum engine steps ────────────────────────────────────────
prefill : 1 step (2,155 ≤ max_num_batched_tokens = 8,192 → one forward pass)
decode : 28 steps (one forward pass per emitted token)
─────────
min steps = 29 steps
general form: 1 + num_output_tokens
enable_prefix_caching=True, turn 1's full prefix (2,152 tok) is reused, so the prefill for turn 2 only computes the 3-tok new role prefix — one cheap forward pass instead of 2,155 tokens of attention. The step count is unchanged (still 1 + 28 = 29); prefix cache saves compute and KV memory, not engine steps.2.2 Synthesized tool-call injection
Continuum's pin estimator classifies the upcoming tool by parsing a trailing ```bash\n<tool_name>\n``` block in the assistant's content. Raw SWE-smith trajectories carry tools in the OpenAI tool_calls field instead, so a preprocessor synthesizes that bash block from tool_calls[0].function.name before tokenization — the extra 5 tokens shown in the example above.
3. Results — Summary Table (avg job duration, seconds)
Below: mean total turn duration per job including queue wait, across 100 jobs × ~18 turns. Lower = better. Bold highlights per-row winner.
H100 80GB
| JPS | fcfs | continuum | cpu_off-16G | cpu_off-128G | lmcache-16G | lmcache-128G |
|---|---|---|---|---|---|---|
| 1 | 41.0 | 41.3 | 50.5 | 41.6 | 57.9 | 53.1 |
| 3 | 232.9 | 69.0 | 232.3 | 79.8 | 260.6 | 96.3 |
| 6 | 276.0 | 75.8 | 268.4 | 85.3 | 297.5 | 105.0 |
| 10 | 281.0 | 79.1 | 290.3 | 91.8 | 319.4 | 105.7 |
A100 PCIE 40GB / 80GB (mixed — see annotations)
| JPS | fcfs | continuum | cpu_off-16G | cpu_off-128G | lmcache-16G | lmcache-128G |
|---|---|---|---|---|---|---|
| 1 | 707.7 (80G) | 188.4 (80G) | 959.2 (40G) | 202.8 (80G) | 680.9 (80G) | 256.9 (80G) |
| 3 | 1086.5 (40G) | 231.4 (40G) | 1057.2 (40G) | 234.2 (80G) | 1144.3 (40G) | 466.5 (40G) |
| 6 | 966.3 (80G) | 233.3 (40G) | 1057.3 (40G) | 241.6 (80G) | 1168.3 (40G) | 310.4 (80G) |
| 10 | 895.7 (80G) | 238.0 (40G) | 1419.2 (40G) | 240.9 (80G) | 1159.0 (40G) | 292.8 (80G) |
gpu-a100 partition mixes A100 40GB and A100 80GB cards. A bare --gres=gpu:a100:1 request can land on either variant, which roughly doubles the available KV budget (~90K → ~200K tokens at 16k ctx) and silently shifts the policy spectrum — particularly the cpu_offload / lmcache crossover. The 24 cells above were not filtered: each landed on whichever SKU was free at submit time (tagged inline per cell; overall 12 × 40G + 12 × 80G). To reproduce cleanly, pin the exact SKU (e.g. --constraint=A100-40GB) instead of letting the scheduler pick.H200 141GB
| JPS | fcfs | continuum | cpu_off-16G | cpu_off-128G | lmcache-16G | lmcache-128G |
|---|---|---|---|---|---|---|
| 1 | 39.6 | 40.1 | 45.7 | 37.2 | 53.1 | 47.3 |
| 3 | 58.3 | 57.2 | 69.3 | 61.6 | 84.3 | 61.3 |
| 6 | 62.1 | 65.0 | 76.6 | 64.7 | 97.0 | 66.5 |
| 10 | 66.1 | 66.3 | 80.8 | 67.1 | 95.6 | 85.6 |
3.1 H100 80GB — 9-chart panel
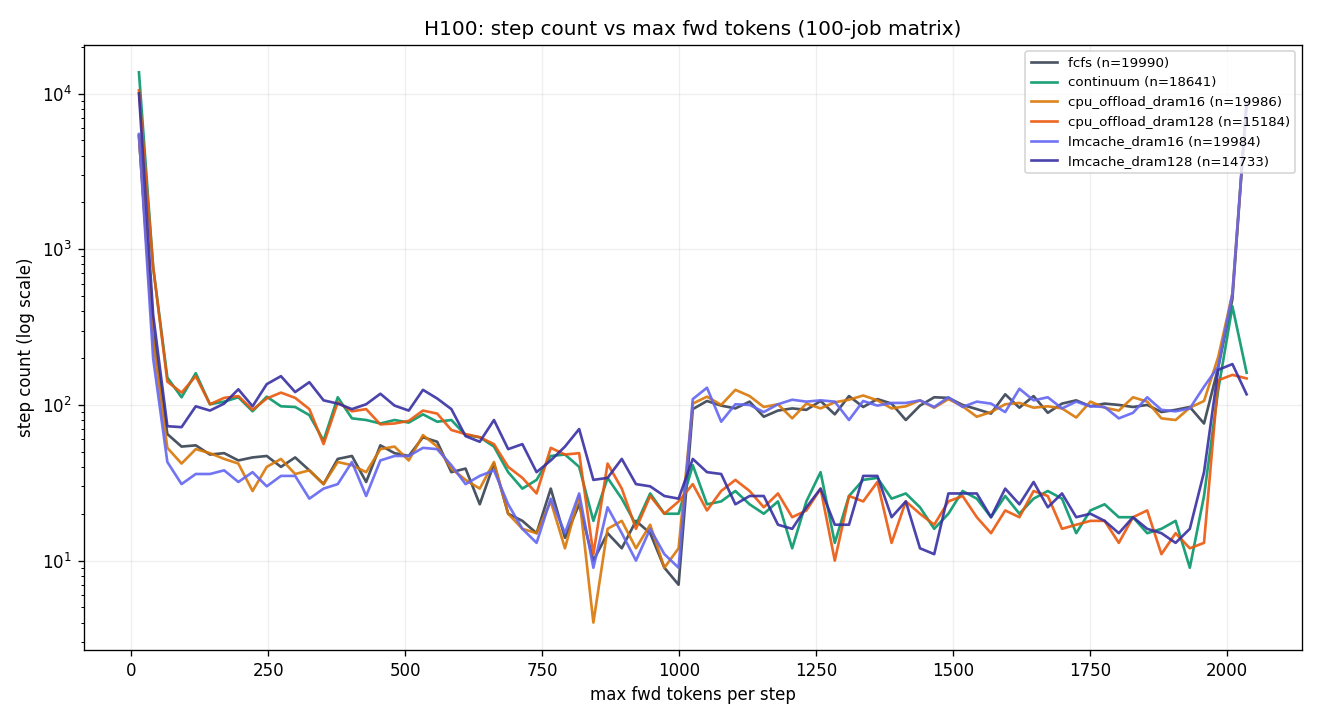
max_num_scheduled_tokens. Continuum and cpu_offload_128G show tighter distributions; cpu_offload_16G and lmcache_16G have heavier right tails due to prefill retries after eviction.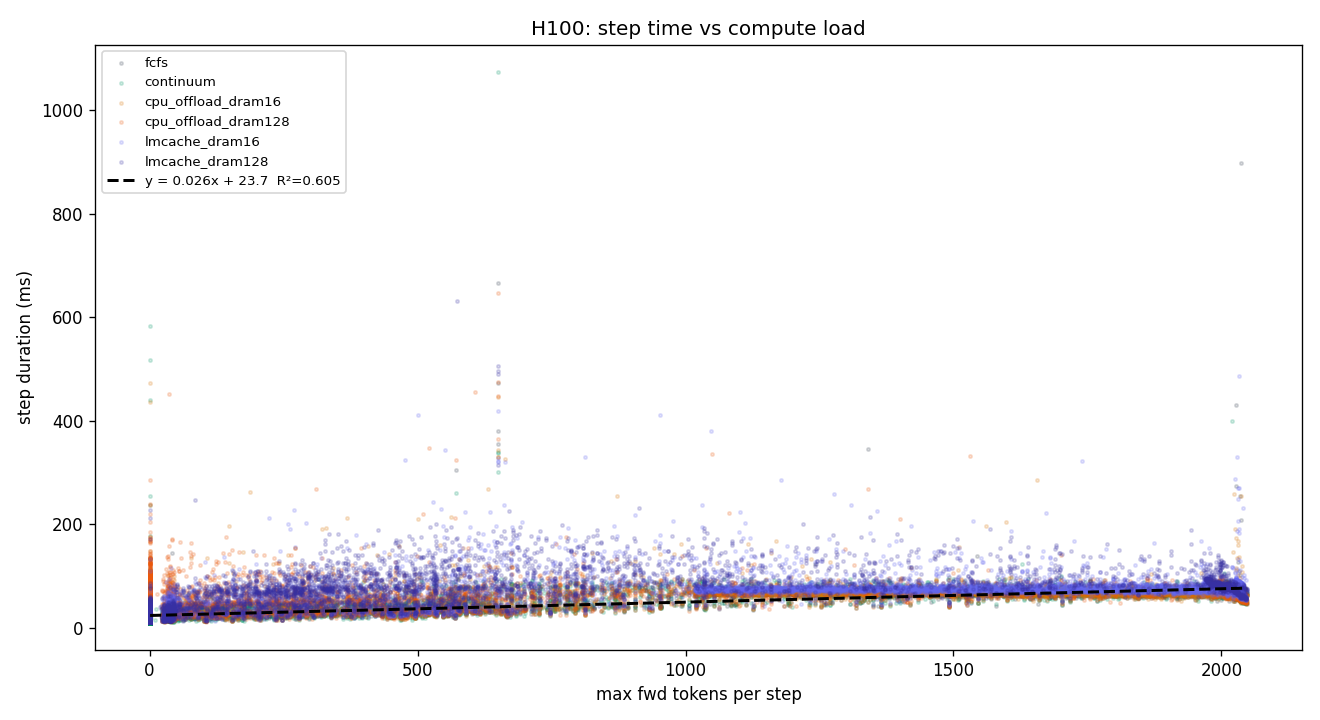
y = 0.0258·x + 23.7, R² = 0.605. Interpretation: each additional token costs ~26 μs of step time; the 24 ms intercept is fixed per-step overhead (kernel launch + scheduler + Python dispatch).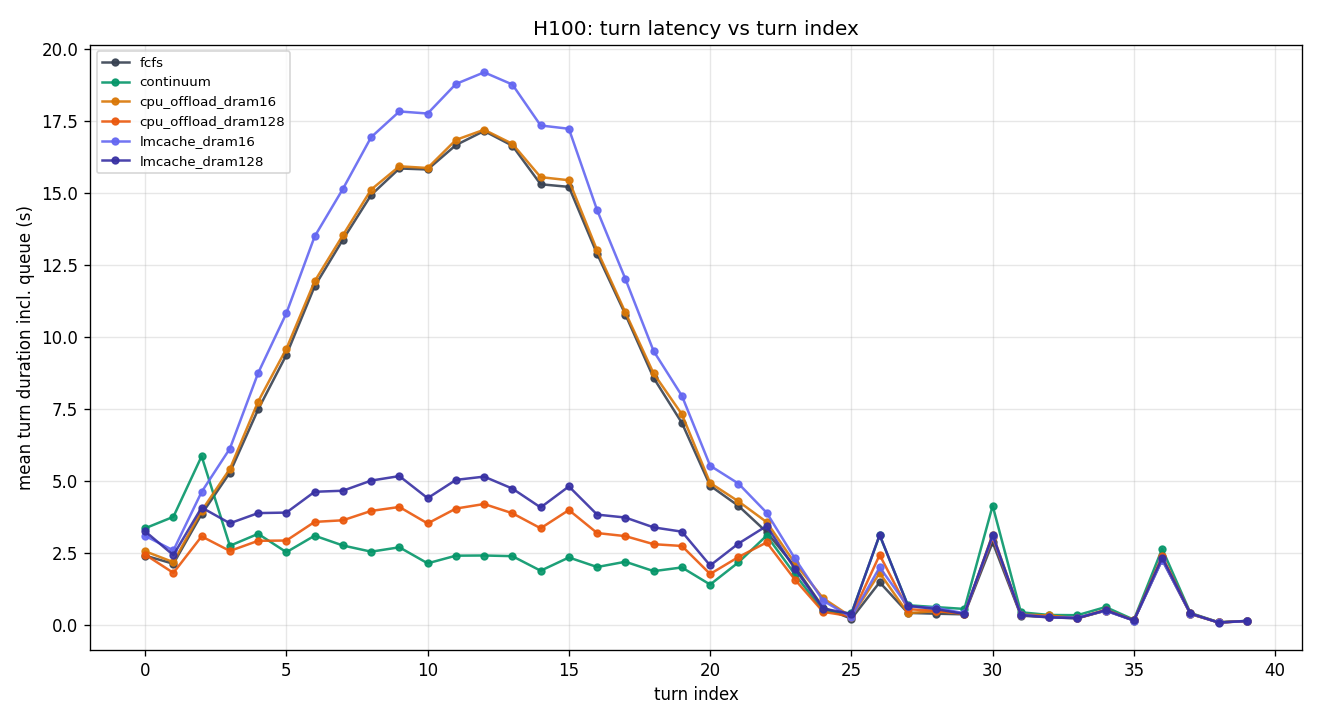
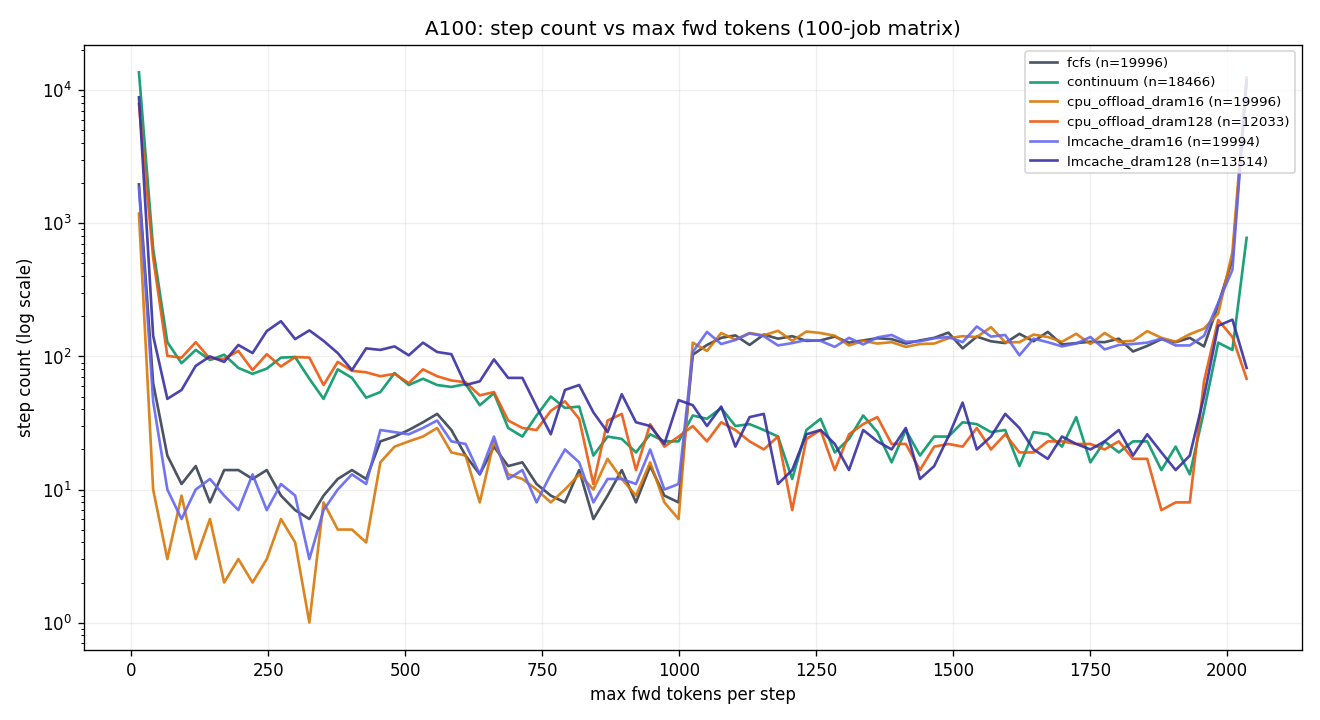
3.2 A100 PCIE 40GB — 9-chart panel
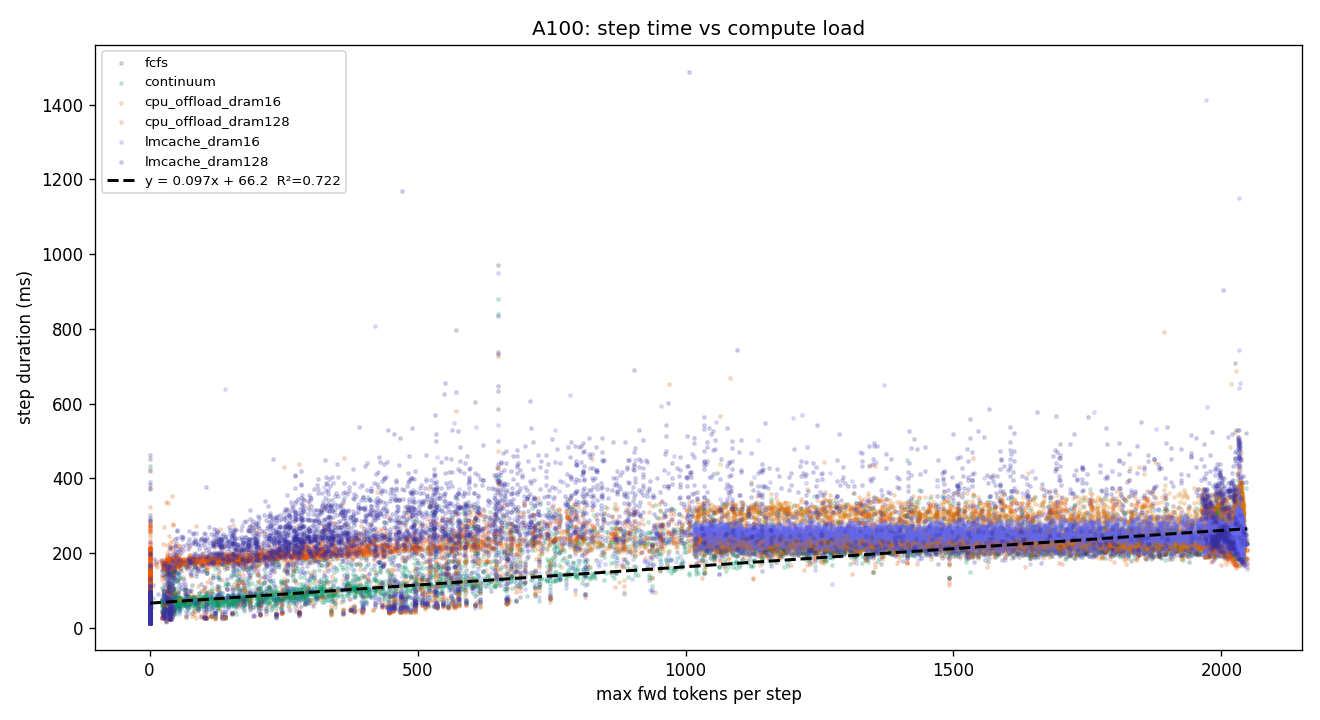
y = 0.0973·x + 66.2 ms, R² = 0.722. A100 is 3.8× slower per token than H100 (26 μs → 97 μs) and has 2.8× higher per-step overhead (24 → 66 ms) — reflecting slower PCIe 4.0 + weaker TensorCore throughput.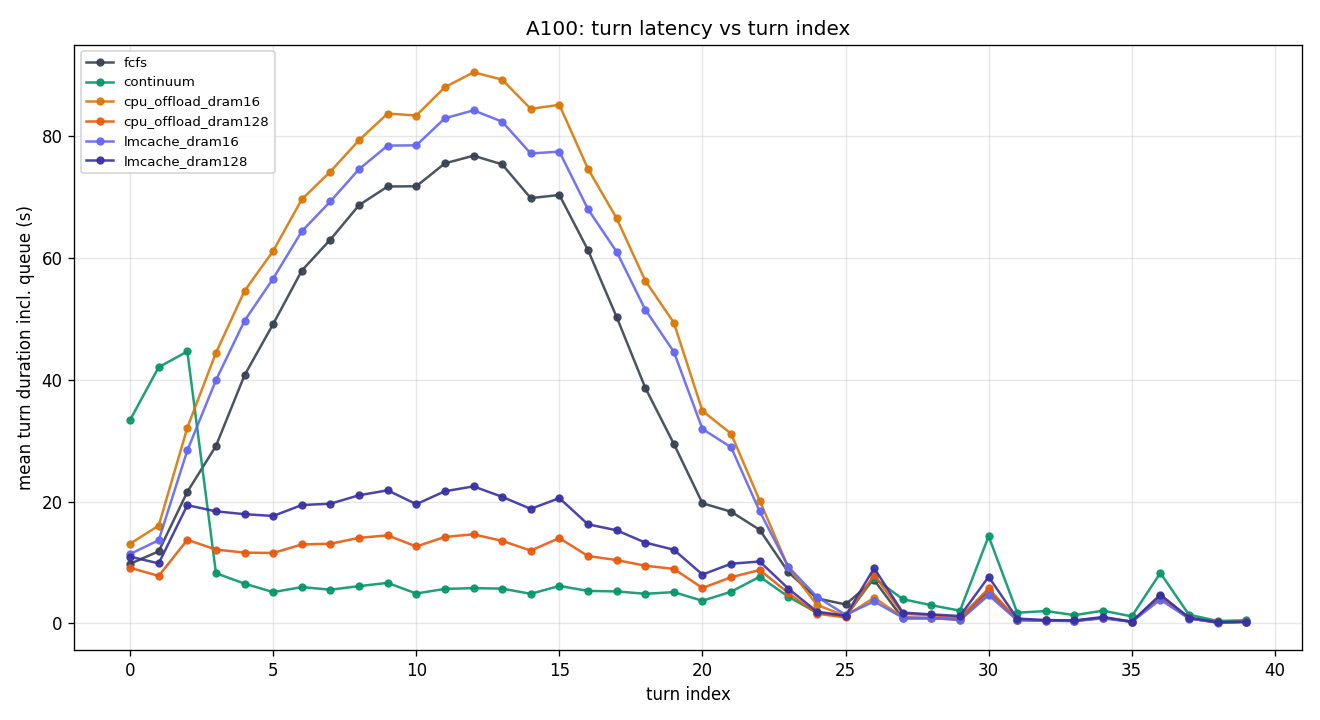
3.3 H200 141GB — 9-chart panel
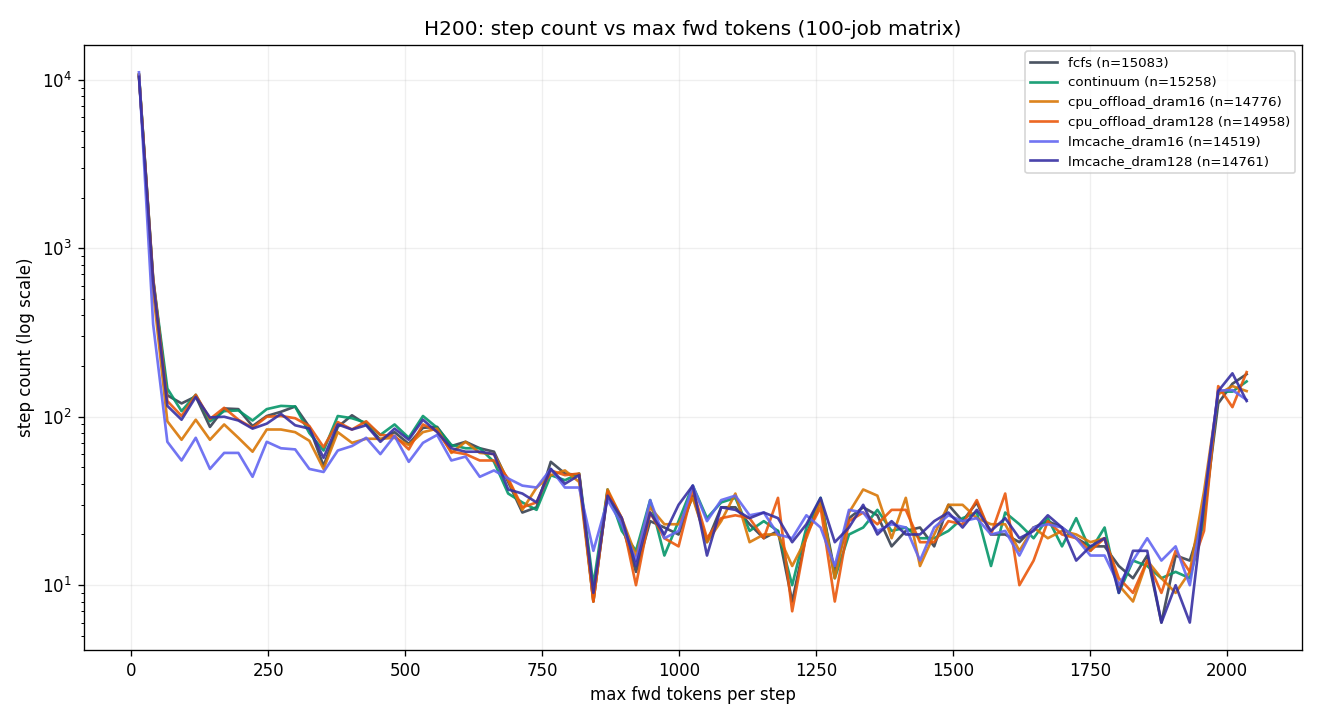
lmcache_16G is the only outlier — deliberately tight DRAM forces external-cache thrash even when GPU KV is plentiful.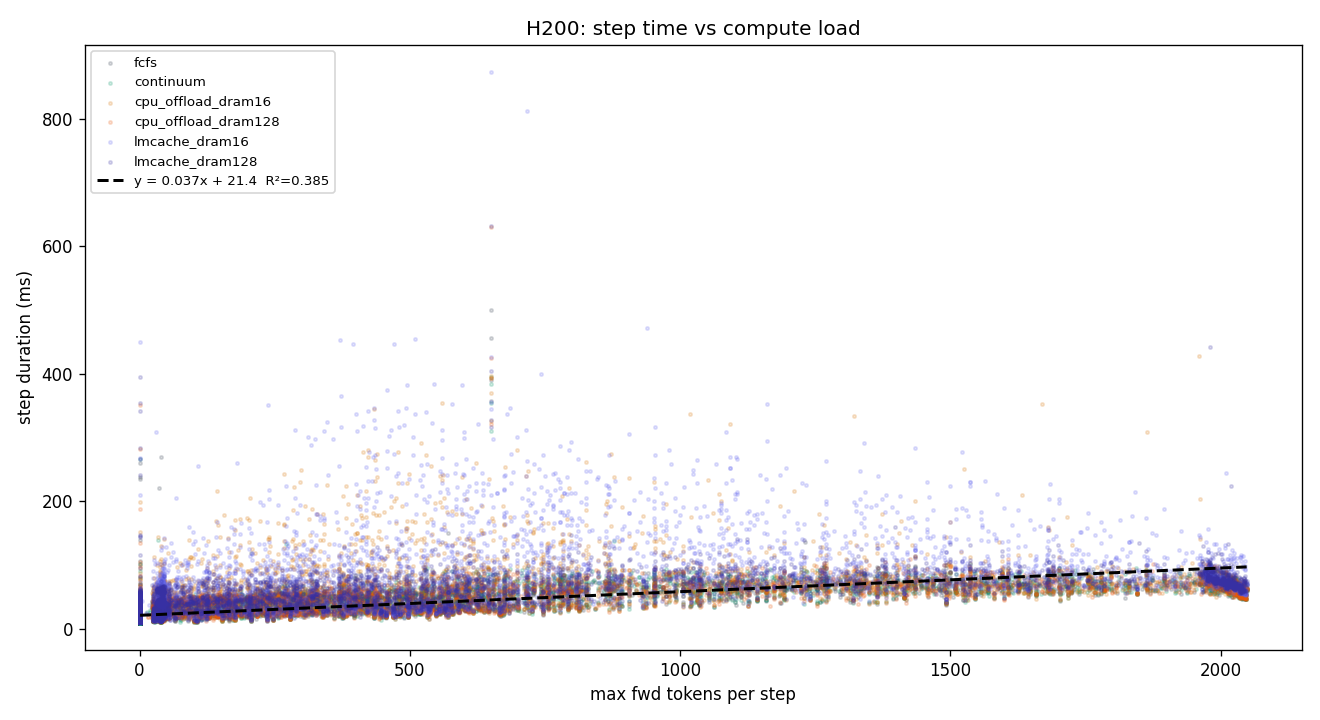
y = 0.0371·x + 21.4 ms, R² = 0.385. Notably lower R² than H100/A100 — compute is so fast that per-step variance is dominated by non-compute factors (scheduler overhead, I/O, Python GIL), not max fwd tokens. Per-token cost (37 μs) is 1.4× H100's, but intercept (21 ms) is actually lower — H200's kernel launch overhead is smaller.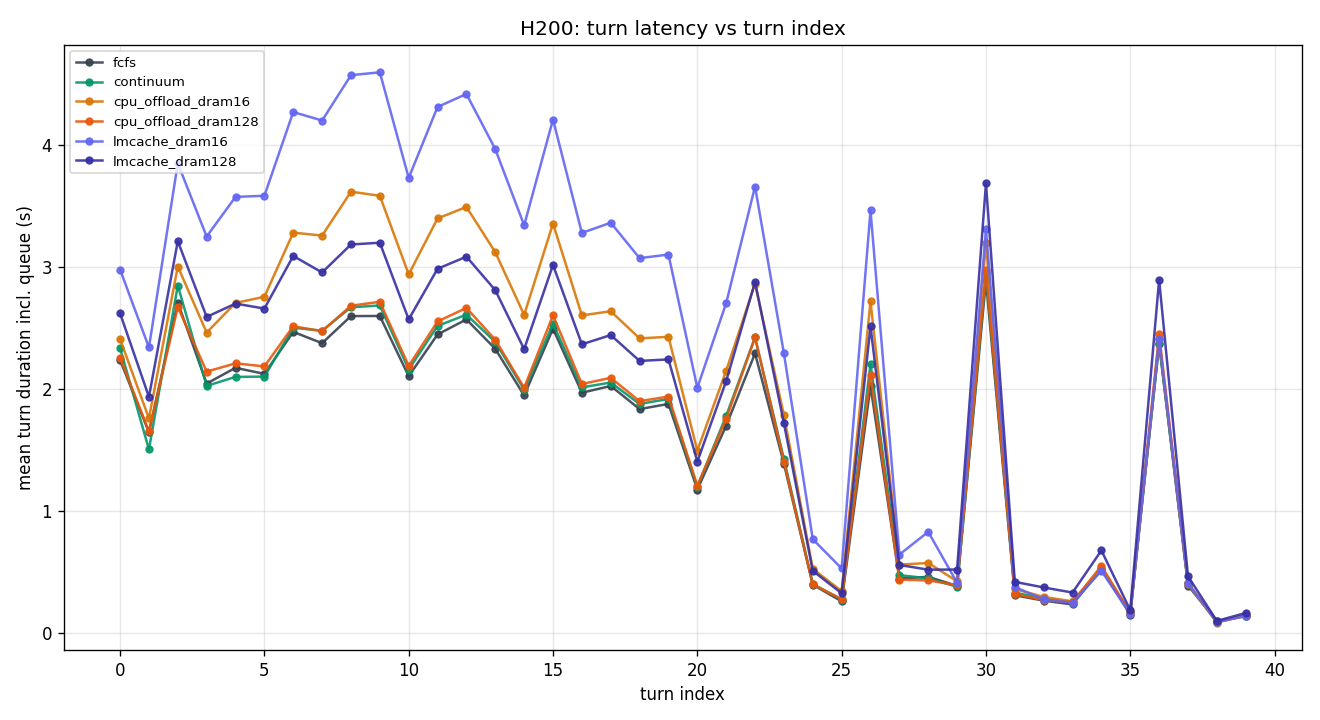
lmcache_16G and cpu_offload_16G (which still suffer from forced eviction). Confirms that policy matters only when KV pressure exists.4. Regression Analysis — Compute Cost Model
Fitting step_duration = slope·max_fwd_tokens + intercept across all policies on each GPU:
| GPU | n (steps) | slope (μs/token) | intercept (ms) | R² | Interpretation |
|---|---|---|---|---|---|
| H100 | 108,518 | 25.8 | 23.7 | 0.605 | Compute-bound: throughput predicts time well. |
| A100 | 103,999 | 97.3 | 66.2 | 0.722 | Strongest linear fit — compute fully saturates kernels. |
| H200 | 89,355 | 37.1 | 21.4 | 0.385 | Compute too fast — overhead dominates step time. |
5. Takeaways
Continuum wins decisively on tight-KV GPUs
H100 JPS ≥ 3: 3.3–3.7× faster than FCFS. A100 JPS ≥ 3: 3.7–4.7× faster. The gain comes from pinning held-KV for 2 s, which lets the next turn of a job hit prefix cache at ~98% instead of re-prefilling 6–8 K tokens.
cpu_offload_128G is a viable Continuum alternative
When DRAM is abundant (≥ working-set size), SimpleCPUOffloadConnector achieves 80–90% of Continuum's latency without any custom scheduling logic. It even surpasses Continuum on H200 (where DRAM transfer cost is trivial vs. compute). However, it cannot replace Continuum on A100 at JPS = 10 (240 s vs 238 s — tied) because PCIe 4.0 becomes the bottleneck.
Undersized DRAM is worse than no DRAM
cpu_offload_16G and lmcache_16G consistently underperform FCFS (which has no external tier) on H100 and A100 at high JPS. LRU thrashes: KV is offloaded then immediately evicted before reuse, paying transfer cost both ways with no benefit. Rule of thumb: DRAM must exceed the sum of all concurrent jobs' peak KV, not average.
H200 makes policy selection moot
With 141 GB HBM3e, the entire 100-job working set fits in VRAM. All policies converge within ±8% of FCFS. Buying H200 is effectively buying insensitivity to scheduler bugs.
5.1 Engineering issues surfaced by this matrix
- Scheduler assertion crash under heavy KV pressure (A100 40GB + Continuum):
vllm/v1/core/sched/scheduler.py:1021assertssum(scheduled_*_req_ids) ≤ len(self.running). Under extreme contention the invariant temporarily breaks. Downgraded to a warning; no downstream effect observed. - vLLM cache grows in $HOME silently: vLLM writes ~10 GB of compile cache into
~/.cache/vllm, which overflows PACE's 20 GB home quota after ~5 runs. Root cause:XDG_CACHE_HOMEalone is insufficient — vllm hardcodesPath.home() / '.cache' / 'vllm'. Fix:export VLLM_CACHE_ROOT=<scratch-dir>/vllmalongsideXDG_CACHE_HOME. - SimpleCPUOffloadConnector extra_config key: Docs reference
cpu_kv_cache_size_bytes; actual code readscpu_bytes_to_use_per_rank. Using the wrong key silently caps CPU KV at 0, forcing GPU-only behavior. - Slurm default --gres=gpu:1 can route to V100: V100 (sm_70) cannot load vLLM 0.19 (FlashAttention 2 requires sm_80+). Must pin
--gres=gpu:h100:1or:a100:1explicitly.
5.2 What we did not measure (limitations)
- Tool exec delay is uniform 1 s. Real tools (
find/grep/python) span 0.01 s (cd) to 60 s (pytest). A per-tool-type distribution would test Continuum's dynamic pin-TTL more faithfully. - No long-context (>16K) jobs included. Llama-3.1-8B supports 128K; tight-KV GPUs would be hit even harder and policy gaps would widen.
- Each run used a single GPU. Tensor parallel / pipeline parallel interactions with Continuum pin are untested.
- No correctness validation. Forced decoding by construction reproduces recorded tokens; a real-agent replay (sampling-free) would surface scheduling-induced quality drift if any.
7. Interactive Trace Viewer
Every run produces per-step JSONL traces (step_snapshot + step_decision + prefix_cache_lookup). Load them into the interactive scheduler trace viewer to inspect individual steps, prefill/decode phases, KV block allocation, pin state, and admission limits.
~/Project/Agentic_KVCache_management/sched_trace_viewer.html
Open in browser, then load sched_trace.<policy>.steps.jsonl + .requests.jsonl from any run directory under results/matrix_100job_{h100,a100,h200}/<policy>_jps<N>/.
Viewer features
- Per-step running/waiting queue with pill badges: category (new/running/resumed/preempted/skipped), turn index, KV blocks held, decode age
- Prefill progress:
[prefill:Nb(Mt), Tt total, P% cached, fwd:Xt] - VRAM block info: free / used (split into pin + active) / total
- DRAM block info (CPU offload / LMCache runs)
- Token budget:
tok:X/Ywith admission-limit reason badges (tok-budget,kv-insuf,max-seqs) - Prefix cache hit per request:
hit:N/M(P%)with local/external split when connector is present - Pin list with job IDs, de-duplicated per job