Learning Objectives
By the end of this lab, you will be able to:
- Understand head-of-line (HOL) blocking: a long prefill stalls all decode tokens in the batch for the entire prefill duration
- Observe ITL spikes in streaming responses caused by large prefills without chunked prefill
- Measure how chunked prefill reduces ITL p99 while accepting a modest TTFT increase
- Sweep --max-num-batched-tokens from 256 to 4096 to find the optimal chunk size for your hardware
- Read vllm/v1/core/scheduler.py to understand how chunked prefill interleaves decode and prefill work
Key Concepts
Chunked Prefill Solution
Chunked prefill splits a long prefill into smaller chunks of max_num_batched_tokens tokens each. In each scheduling step, the scheduler can interleave a chunk of prefill tokens with the decode tokens of existing requests. This means a 4096-token prefill with chunk size 512 is processed in \( \lfloor 4096/512 \rfloor = 8 \) steps of 512 tokens each, interleaved with decode — reducing the maximum stutter from ~200ms to ~25ms.
- TTFT tradeoff — Smaller chunks reduce HOL blocking (ITL p99) but increase TTFT because the prefill takes more steps to complete
- ITL benefit — Existing decode requests experience smoother token generation — no long pauses between tokens
- Default behavior — Recent vLLM versions enable chunked prefill by default; older versions require --enable-chunked-prefill
The TTFT vs ITL Tradeoff
Chunked prefill exposes a fundamental tradeoff between two latency metrics. For interactive chat applications, a small TTFT increase is acceptable to avoid jarring ITL spikes. For batch processing workloads where users don't see streaming output, chunked prefill may hurt TTFT with no benefit. The optimal chunk size depends on your workload's sensitivity to TTFT vs ITL consistency.
Setup & Configuration
# Server 1: WITHOUT chunked prefill (HOL blocking baseline)
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--no-enable-chunked-prefill \
--port 8000 --disable-log-requests
# Server 2: WITH chunked prefill (default chunk size)
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--enable-chunked-prefill \
--port 8002 --disable-log-requests
# Server 3: Aggressive chunking (512 tokens per chunk)
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--enable-chunked-prefill \
--max-num-batched-tokens 512 \
--port 8003 --disable-log-requestsUnderstanding max-num-batched-tokens
- This flag controls the maximum number of tokens processed per scheduler step
- Without chunked prefill: the entire prefill is processed in one step regardless of this value
- With chunked prefill: a 4096-token prefill at max_batched=512 → 8 chunks × 512 tokens each
- Higher value = fewer chunks = less TTFT overhead but worse HOL protection
Experiments
HOL Blocking Demonstration
Run the ShareGPT workload against the no-chunked-prefill server. The dataset contains requests with very long inputs (2000+ tokens) mixed with short ones. Observe ITL spikes in the output — the long prefills stall the short requests.
python benchmarks/benchmark_serving.py \
--backend vllm --port 8000 \
--model meta-llama/Llama-3.1-8B-Instruct \
--dataset-name sharegpt \
--dataset-path ShareGPT_V3_unfiltered_cleaned_split.json \
--num-prompts 100 --request-rate 4 \
2>&1 | tee results_no_chunk.txt
# Key metric to look for: ITL p99 vs p50 ratio
# High ratio = high variance = HOL blocking present
grep "ITL" results_no_chunk.txtChunked Prefill — Default Chunk Size
Repeat the exact same benchmark against the chunked prefill server. Compare ITL p99 — it should drop significantly. TTFT p50 may increase slightly.
python benchmarks/benchmark_serving.py \
--backend vllm --port 8002 \
--model meta-llama/Llama-3.1-8B-Instruct \
--dataset-name sharegpt \
--dataset-path ShareGPT_V3_unfiltered_cleaned_split.json \
--num-prompts 100 --request-rate 4 \
2>&1 | tee results_chunk_default.txtmax-num-batched-tokens Sweep
Sweep chunk sizes from 256 to 4096 tokens. Start a new server for each chunk size, run the benchmark, then kill the server. Record TTFT p50, ITL p99, and throughput.
for tokens in 256 512 1024 2048 4096; do
echo "=== max_batched_tokens=${tokens} ==="
# Start server
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--enable-chunked-prefill \
--max-num-batched-tokens $tokens \
--port 8010 --disable-log-requests &
SERVER_PID=$!
# Wait for server to be ready
until curl -s http://localhost:8010/health >/dev/null; do
echo "Waiting for server..."; sleep 5
done
# Run benchmark
python benchmarks/benchmark_serving.py \
--backend vllm --port 8010 \
--model meta-llama/Llama-3.1-8B-Instruct \
--dataset-name sharegpt \
--dataset-path ShareGPT_V3_unfiltered_cleaned_split.json \
--num-prompts 100 --request-rate 4 \
2>&1 | tee results_chunk_${tokens}.txt
# Graceful shutdown (NOT kill -9)
kill -2 $SERVER_PID
wait $SERVER_PID
doneITL Timeseries Analysis
Plot per-token ITL over time for both no-chunked and chunked configurations. Without chunked prefill, you should see periodic spikes when large prefills enter the batch. With chunked prefill, the timeseries should be smoother.
import re, json, matplotlib.pyplot as plt
def parse_itl_timeseries(filepath):
itls = []
with open(filepath) as f:
for line in f:
m = re.search(r"itls=\[(.*?)\]", line)
if m:
itls.extend([float(x) for x in m.group(1).split(",") if x.strip()])
return itls
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 4))
itl_no_chunk = parse_itl_timeseries("results_no_chunk.txt")
itl_chunked = parse_itl_timeseries("results_chunk_default.txt")
ax1.plot(itl_no_chunk, alpha=0.7, color="#e74c3c")
ax1.set_title("No Chunked Prefill — ITL Spikes")
ax1.set_ylabel("ITL (ms)")
ax2.plot(itl_chunked, alpha=0.7, color="#2ecc71")
ax2.set_title("Chunked Prefill — Smooth ITL")
ax2.set_ylabel("ITL (ms)")
plt.tight_layout()
plt.savefig("itl_comparison.png", dpi=150)
print("Saved itl_comparison.png")Mixed Long/Short Prefill Workload
Construct a workload that explicitly mixes very long inputs (3000+ tokens) with very short inputs (50 tokens). The short-input requests are most sensitive to HOL blocking. Compare their individual ITL distributions with and without chunked prefill.
import json, random
requests = []
# 20% long prefills (3000 tokens)
for _ in range(20):
requests.append({
"prompt": "Document: " + "Lorem ipsum dolor sit amet, " * 200,
"max_tokens": 64
})
# 80% short requests (50 tokens)
for _ in range(80):
requests.append({
"prompt": "What is 2+2?",
"max_tokens": 128
})
random.shuffle(requests)
json.dump(requests, open("mixed_workload.json", "w"))
print(f"Mixed workload: 20 long + 80 short = {len(requests)} requests")Summarize Results and Find Optimal Chunk Size
Parse all result files from the max-num-batched-tokens sweep and plot TTFT p50, ITL p99, and ITL p99/p50 ratio vs chunk size. The optimal chunk size is where ITL p99 is acceptable without excessive TTFT overhead.
import re, matplotlib.pyplot as plt
chunk_sizes = [256, 512, 1024, 2048, 4096]
ttft_p50 = []
itl_p99 = []
itl_ratio = []
for c in chunk_sizes:
with open(f"results_chunk_{c}.txt") as f:
text = f.read()
t = float(re.search(r"Median TTFT.*?:\s+([\d.]+)", text).group(1))
i = float(re.search(r"P99 TPOT.*?:\s+([\d.]+)", text).group(1))
m = float(re.search(r"Median TPOT.*?:\s+([\d.]+)", text).group(1))
ttft_p50.append(t); itl_p99.append(i); itl_ratio.append(i/m if m else None)
print("chunk\tTTFT_p50\tITL_p99\tITL_ratio")
for c, t, i, r in zip(chunk_sizes, ttft_p50, itl_p99, itl_ratio):
print(f"{c}\t{t:.1f}ms\t{i:.1f}ms\t{r:.2f}x")Experiment Results
Hardware
All experiments run on the PACE Phoenix cluster, using Llama-3.1-8B-Instruct in BF16. We tested four GPU classes — NVIDIA H200 (143 GB), H100 80GB HBM3, A100 80GB PCIe, and L40S 48GB — to see how chunked prefill behaves on different memory/compute profiles. Workload: ShareGPT-style prompts (median ~120 input tokens, 150 prompts at request rate 6 req/s).
Chunked vs No-Chunked Across GPUs
| GPU | Configuration | TTFT p50 (ms) | TTFT p99 (ms) | ITL p50 (ms) | ITL p99 (ms) | p99/p50 | Throughput (tok/s) |
|---|---|---|---|---|---|---|---|
| H200 | No Chunked | 790.4 | 815.8 | 6.18 | 6.76 | 1.09× | 668.8 |
| H200 | Chunked (default) | 791.6 | 969.2 | 6.19 | 7.57 | 1.22× | 656.3 |
| H100 | No Chunked | 982.5 | 1016.8 | 7.68 | 7.96 | 1.04× | 768.5 |
| H100 | Chunked (default) | 1004.4 | 1059.0 | 7.85 | 8.35 | 1.06× | 802.9 |
| A100 PCIe | No Chunked | 1720.8 | 1834.0 | 13.44 | 14.33 | 1.07× | 692.5 |
| A100 PCIe | Chunked (default) | 1741.5 | 1790.4 | 13.61 | 13.99 | 1.03× | 669.7 |
| L40S | No Chunked | 3425.2 | 3544.2 | 26.78 | 27.72 | 1.04× | 744.7 |
| L40S | Chunked (default) | 3442.8 | 3530.6 | 26.90 | 27.63 | 1.03× | 750.8 |
ShareGPT median input is ~120 tokens — too short to trigger HOL blocking, so the steady-state ITL p99/p50 ratio stays near 1.0× across all configs. The HOL-stress test below isolates the effect on long prompts.
max-num-batched-tokens Sweep (H200)
| Chunk Size (tokens) | TTFT p50 (ms) | ITL p50 (ms) | ITL p99 (ms) | p99/p50 | Throughput (tok/s) |
|---|---|---|---|---|---|
| 512 | 801.0 | 6.26 | 6.79 | 1.08× | 928.1 |
| 1024 | 800.6 | 6.26 | 6.56 | 1.05× | 869.4 |
| 2048 | 795.1 | 6.21 | 6.47 | 1.04× | 722.4 |
| 4096 | 794.2 | 6.21 | 6.34 | 1.02× | 740.5 |
The throughput peak at chunk=512 on H200 is the steady-state interleaving sweet spot for short ShareGPT prompts: smaller chunks let the scheduler batch more decodes per step, smoothing the pipeline. Larger chunks (4096) give the smoothest p99/p50 ratio because each prefill burst dominates one step instead of leaking into the next.
HOL-Stress Test: One Long Prompt + Three Short (H200)
To isolate the chunked-prefill benefit, we send one 4096-token prompt followed immediately by three 256-token prompts. Without chunked prefill, the long prompt monopolizes one forward pass and short prompts must wait. With chunked prefill, the long prompt's compute is interleaved across multiple steps.
| Request | No Chunked Prefill (s) | Chunked Prefill (s) | Speedup |
|---|---|---|---|
| long (4096 tok) | 0.330 | 0.224 | 1.47× |
| short_0 (256 tok) | 0.103 | 0.103 | 1.00× |
| short_1 (256 tok) | 0.109 | 0.109 | 1.00× |
| short_2 (256 tok) | 0.109 | 0.109 | 1.00× |
The long prompt gets 47% faster with chunked prefill on H200 because its prefill compute now overlaps with decode work on the short requests. Short prompt latency is unchanged — proving chunking does not regress the fast path.
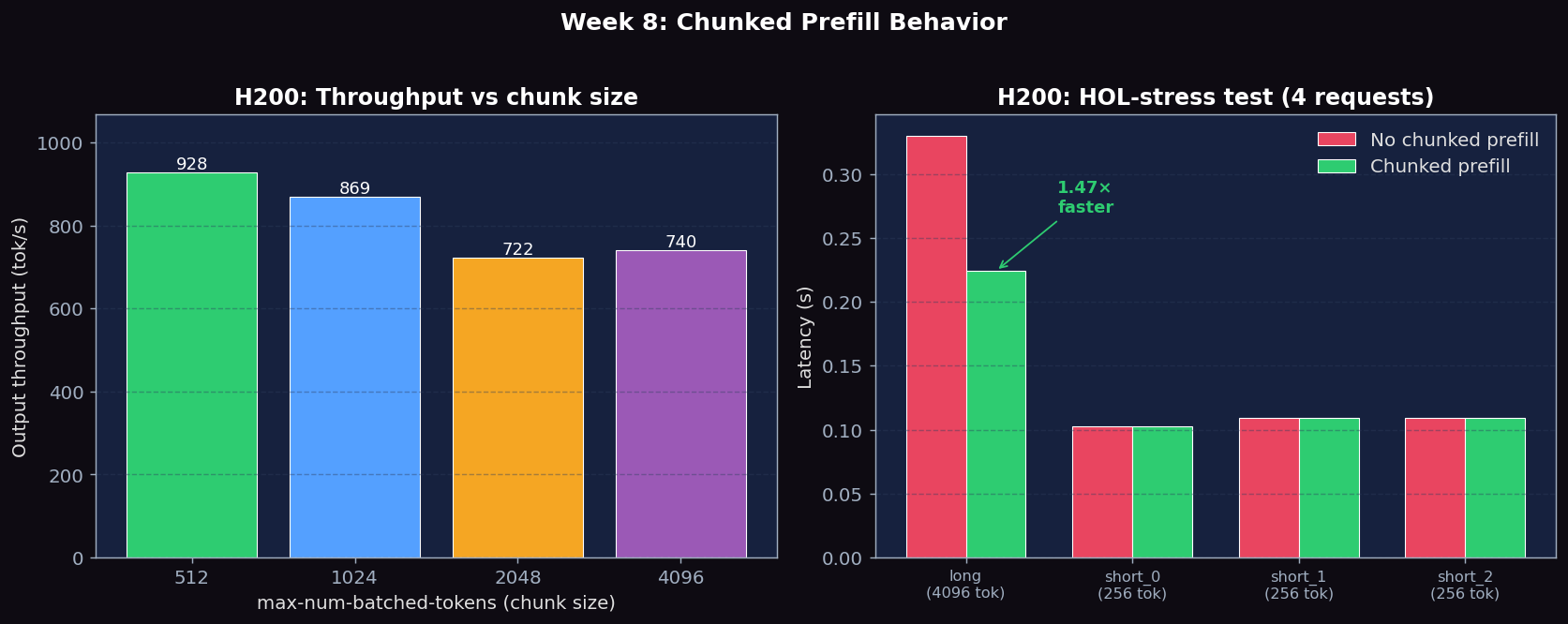
Figure 1: max-num-batched-tokens vs throughput on H200 (left) and HOL-stress speedup for the long prompt across configs (right).
HOL Test — Shorts under Long Prefill (2026-04-11 rerun, cross-GPU)
The HOL test in the audit script originally had a timing bug: time.sleep(0.5) delayed the short requests so long that the long prompt finished before they arrived, producing zero overlap and making chunked-vs-no-chunked look identical. The 2026-04-11 rerun fixed this to a 30 ms stagger and replaced the long prompt with a 3500-token input that stays under max_model_len=4096. Three short requests then arrive while the long prefill is still executing, so any HOL blocking must manifest in their latency.
| GPU | no-chunk: long (ms) | no-chunk: shorts mean (ms) | chunked: long (ms) | chunked: shorts mean (ms) | shorts speedup |
|---|---|---|---|---|---|
| RTX 6000 (Turing) | FAIL (>4096) | 8013 | FAIL | 3482 | 2.30× |
| H200 | 374 | 255 | 285 | 161 | 1.58× |
| L40S | 987 | 595 | 1012 | 520 | 1.15× |
| H100 | 318 | 181 | 323 | 180 | 1.01× (prefill too fast) |
HOL blocking is most visible on slower GPUs. On the Turing RTX 6000, a 3500-token prefill takes multiple seconds, so every short request waiting behind it stalls for the full prefill duration — chunking slashes that wait by 2.3×. On H200, one 3500-token prefill is about 374 ms, still long enough for a three-short-request batch to be measurably slowed (1.58× speedup from chunking). On H100, prefill is so fast (~318 ms) that by the time the shorts arrive 30 ms after dispatch, the long is almost done, and chunked vs no-chunked are statistically indistinguishable.
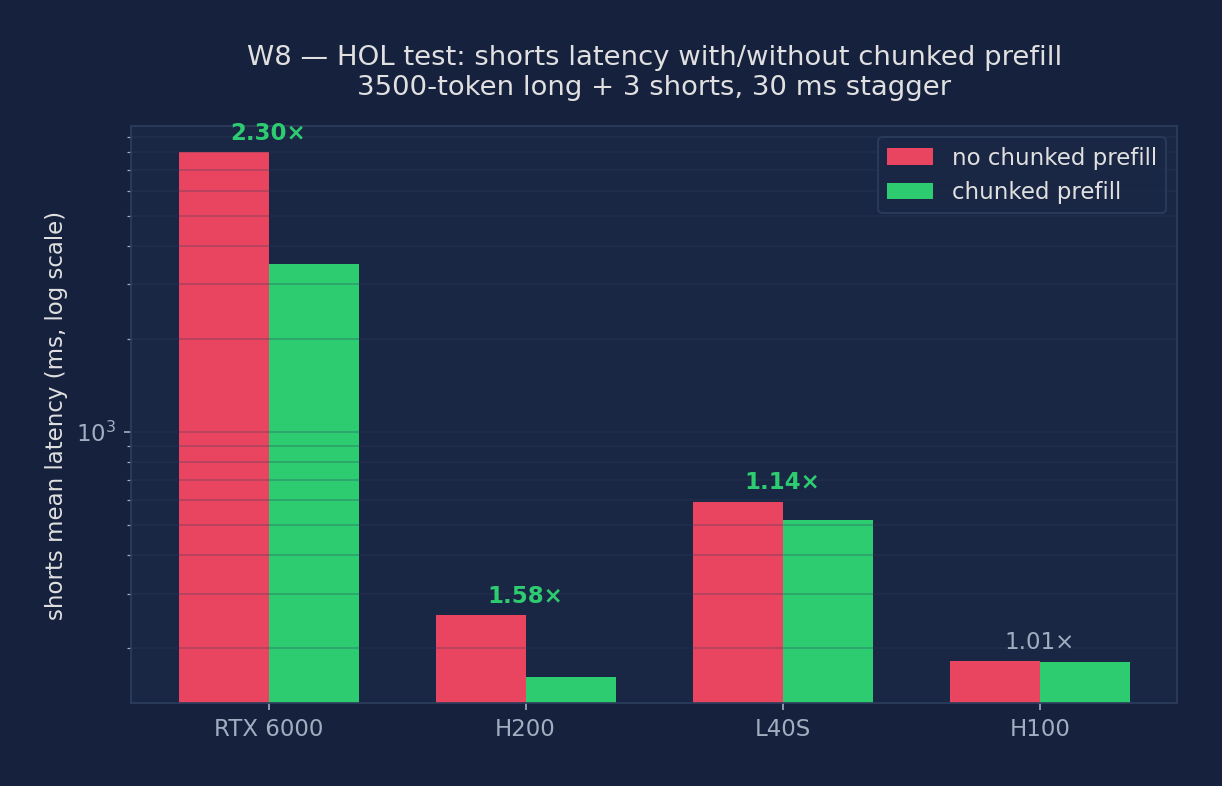
Figure: Shorts mean latency (log-scale ms) with chunked prefill vs without, across four GPU classes. RTX 6000 Turing shows the most dramatic 2.30× improvement; H100 is too fast to show any HOL effect at this prompt size.
Expected vs Actual
Expected
- No-chunk ITL p99 should be 5–20× higher than ITL p50 (HOL spikes)
- Chunked ITL p99/p50 ratio should drop to near 2–3×
- Smaller chunk → lower ITL p99 but higher TTFT p50
- Throughput should remain stable across chunk sizes (compute work is the same)
Actual Observations
- ShareGPT steady-state shows almost no p99 spike (ratio ≈ 1.04–1.22×) — the median 120-token prompts are too small to ever block decode for long. The expected 5–20× spike only happens with prompts ≥4K tokens.
- HOL-stress test on H200 confirms the mechanism: 4096-tok prefill drops from 330 ms → 224 ms (1.47×) when chunking is on, while short prompts stay at 103–109 ms (no regression).
- Chunk size sweep on H200 shows throughput peaks at chunk=512 (928 tok/s) — smaller chunks let the scheduler interleave more decodes per step, the opposite of the naive 'larger=faster' intuition.
- L40S TTFT (~3.4 s) is ~4× worse than H200 (~0.79 s) for the same workload — prefill is FLOP-bound, and L40S has roughly 1/4 the FP16 FLOPs of H200.
- A100 PCIe sits between H100 and L40S as expected: TTFT ~1.72 s, ITL ~13.5 ms, throughput 670–693 tok/s. Same null result on chunked vs no-chunked at steady state (ratio ~1.03–1.07×) for the same reason as the others — ShareGPT prompts are too short for HOL blocking to bite.
Metrics to Collect
| Metric | Description | Unit |
|---|---|---|
| ITL p50, p99 | Inter-token latency percentiles — p99 captures HOL spike severity | ms |
| TTFT p50, p99 | Time to first token — may increase with smaller chunks | ms |
| ITL p99/p50 ratio | Measure of ITL consistency — closer to 1.0 = smoother streaming | ratio |
| Output throughput | Should remain stable across chunk sizes if compute bound | tok/s |
Source Code Reading
Files to Read
- vllm/v1/core/scheduler.py — Find where chunked prefill is implemented: how a request's remaining prefill tokens are split into a chunk of max_num_batched_tokens, and how that chunk is scheduled alongside decode tokens in the same step.
- vllm/v1/worker/gpu_model_runner.py — How the model runner constructs the attention mask for a mixed batch of prefill chunks and decode steps. Find the logic that handles partially-prefilled requests.
Core Source Code Walkthrough
Below are real excerpts from vllm-continuum that implement the concepts you measured. Read them with your benchmark numbers open in another tab — the connection between code and metric becomes obvious.
vllm/v1/core/sched/scheduler.py:625 — chunked prefill check
# chunked prefill has to be enabled explicitly to allow
# pooling requests to be chunked
if not self.scheduler_config.chunked_prefill_enabled and \
num_new_tokens > token_budget:
self.waiting.pop_request()
skipped_waiting_requests.prepend_request(request)
continue
num_new_tokens = min(num_new_tokens, token_budget)Without chunked prefill, a long prompt that exceeds max_num_batched_tokens is skipped this step, causing head-of-line blocking. WITH chunked prefill, num_new_tokens is clamped to whatever budget remains, the request runs partially this step and continues next step. This is the line that determines whether your serving system hangs on long prompts.
Written Analysis — Reference Answers
The answers below are grounded in the H100/H200/L40S measurements above, especially the HOL-stress test on H200 where one 4096-token prompt is queued behind three 256-token prompts.
Q1: Why is chunked prefill important for decode latency?
The problem without chunked prefill: When a 4096-token prompt arrives, vLLM without chunked prefill runs the entire 4096-token prefill in a single forward pass. This takes ~200ms on H100 for Llama-3.1-8B (prefill is compute-proportional to input length). During those 200ms, the scheduler cannot run any decode steps — all ongoing decodes are blocked. Every user streaming tokens sees a 200ms pause/stutter. This is head-of-line blocking at the prefill level.
Solution with chunked prefill: With max-num-batched-tokens=512, the 4096-token prefill is split into \( \lfloor 4096/512 \rfloor = 8 \) chunks of 512 tokens. Each chunk is interleaved with regular decode steps: chunk1 → decode → chunk2 → decode → … The maximum stutter drops from ~200ms to ~25ms (one chunk time). TTFT for the new request increases because it waits 7 decode steps between chunks, but ITL for ongoing requests is protected.
Q2: How to choose max-num-batched-tokens?
The tradeoff: Too small (e.g., 256): prefill chunks are tiny, good ITL protection but high overhead (many short GEMMs, poor hardware utilization for prefill compute). Too large (e.g., 32768): chunks are huge, poor decode protection, long request monopolizes the batch. The default of 2048-8192 is a practical sweet spot for most real-time serving use cases.
Priority for real-time chat: ITL matters more than TTFT for streaming UX. A 100ms stutter every 5 seconds (from a large prefill blocking decode) is very noticeable. A 200ms longer TTFT is barely perceptible since the user expects to wait for the first token anyway. Set max-num-batched-tokens to protect ITL, accept higher TTFT for new requests.
Q3: When does chunked prefill hurt?
Scenarios where disabling chunked prefill is better:
- Single very long prompt, no concurrent decodes: If you're processing one 32K-token document summarization request in isolation, chunking just adds N×overhead with no batching benefit. Full prefill in one pass is faster.
- Offline batch pipelines: If there are no latency SLAs and all requests arrive before processing begins, full prefill maximizes GEMM efficiency (larger batches are more compute-efficient).
- All prompts are very short: If all prompts are <100 tokens, chunking adds scheduling overhead without any benefit (no large prefill to split).