Learning Objectives
By the end of this lab, you will be able to:
- Understand SGLang's RadixAttention — a radix tree for token-level KV cache reuse
- Compare RadixAttention (SGLang) vs APC (vLLM) on few-shot workloads
- Experiment with LPM (Longest Prefix Match) vs FCFS scheduling and measure the impact on throughput
- Write a multi-turn conversation using the sgl.function DSL and observe prefix reuse across turns
- Read sglang/srt/mem_cache/radix_cache.py and understand match_prefix() at token granularity
Key Concepts
RadixAttention vs vLLM APC
| Feature | SGLang RadixAttention | vLLM APC |
|---|---|---|
| Granularity | Token-level | Block-level (16 tokens) |
| Matching algorithm | Radix tree traversal | Hash lookup |
| Non-aligned prefix | Full reuse | Only full blocks reused |
| Scheduling policy | LPM / FCFS / DFS-weight | FCFS |
LPM Scheduling Intuition
With LPM (Longest Prefix Match) scheduling, SGLang prioritizes requests that share the longest cached prefix. This batches similar requests together — maximizing cache hits per scheduling step. On shared-prefix workloads (e.g., few-shot examples, RAG), LPM can dramatically improve throughput and cache hit rate compared to FCFS, which schedules purely by arrival order.
Setup & Configuration
# SGLang with radix cache ENABLED (default, port 8001)
python -m sglang.launch_server \
--model meta-llama/Llama-3.1-8B-Instruct \
--port 8001
# SGLang with radix cache DISABLED (baseline, port 8004)
python -m sglang.launch_server \
--model meta-llama/Llama-3.1-8B-Instruct \
--disable-radix-cache \
--port 8004
# SGLang with FCFS scheduling (port 8005)
python -m sglang.launch_server \
--model meta-llama/Llama-3.1-8B-Instruct \
--schedule-policy fcfs \
--port 8005
# vLLM with APC for cross-system comparison (port 8000)
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--enable-prefix-caching \
--port 8000 --disable-log-requestsPrerequisites
- SGLang installed: pip install sglang[all] in a dedicated venv
- vLLM installed (for cross-system comparison in Experiment 4)
- Generated shared-prefix dataset supported by sglang.bench_serving
Experiments
Radix Cache On vs Off — Few-Shot Workload
Run a few-shot benchmark where requests share a long prefix (e.g., 5 examples before the actual question). Radix cache should dramatically reduce TTFT after the first warm-up request.
# Radix cache ON — few-shot workload
python -m sglang.bench_serving \
--backend sglang --port 8001 \
--dataset-name generated-shared-prefix \
--num-prompts 200 --request-rate 4 \
2>&1 | tee results_radix_on.txt
# Radix cache OFF — same workload
python -m sglang.bench_serving \
--backend sglang --port 8004 \
--dataset-name generated-shared-prefix \
--num-prompts 200 --request-rate 4 \
2>&1 | tee results_radix_off.txtLPM vs FCFS Scheduling
SGLang uses LPM scheduling by default. Compare against FCFS by using a server started with --schedule-policy fcfs. Use a higher request rate (8 req/s) to stress the scheduler.
# LPM scheduling (default — port 8001)
python -m sglang.bench_serving \
--backend sglang --port 8001 \
--dataset-name generated-shared-prefix \
--num-prompts 300 --request-rate 8 \
2>&1 | tee results_lpm.txt
# FCFS scheduling (port 8005)
python -m sglang.bench_serving \
--backend sglang --port 8005 \
--dataset-name generated-shared-prefix \
--num-prompts 300 --request-rate 8 \
2>&1 | tee results_fcfs.txtsgl.function DSL — Multi-Turn with Prefix Reuse
Write a multi-turn conversation with sgl.function. Run it 10 times; the first call warms the cache; subsequent calls should show significantly lower TTFT for the shared prefix.
import sglang as sgl
import time
sgl.set_default_backend(sgl.RuntimeEndpoint("http://localhost:8001"))
@sgl.function
def multi_turn(s, question1, question2):
s += sgl.system("You are a helpful assistant.")
s += sgl.user(question1)
s += sgl.assistant(sgl.gen("answer1", max_tokens=256))
s += sgl.user(question2)
s += sgl.assistant(sgl.gen("answer2", max_tokens=256))
# Warmup run (cold cache)
t0 = time.time()
state = multi_turn.run(
question1="What is PagedAttention?",
question2="How does it compare to RadixAttention?")
print(f"Cold run: {time.time()-t0:.3f}s")
print(state["answer1"])
# Warm run (same prefix, different second question)
t1 = time.time()
state2 = multi_turn.run(
question1="What is PagedAttention?",
question2="What are its memory advantages?")
print(f"Warm run: {time.time()-t1:.3f}s")
print(state2["answer2"])vLLM APC vs SGLang Radix — Head-to-Head
Run the same generated-shared-prefix workload against vLLM APC (port 8000) and SGLang Radix (port 8001) and compare TTFT, throughput, and cache hit rate.
# vLLM APC benchmark
python benchmarks/benchmark_serving.py \
--backend vllm --port 8000 \
--model meta-llama/Llama-3.1-8B-Instruct \
--dataset-name generated-shared-prefix \
--num-prompts 200 --request-rate 4 \
2>&1 | tee results_vllm_apc.txt
# SGLang RadixAttention benchmark
python -m sglang.bench_serving \
--backend sglang --port 8001 \
--dataset-name generated-shared-prefix \
--num-prompts 200 --request-rate 4 \
2>&1 | tee results_sglang_radix.txtVary Number of Few-Shot Examples
Control the number of few-shot examples in the shared prefix (1, 3, 5, 10 examples). More examples means a longer shared prefix and higher potential cache savings.
for num_shots in 1 3 5 10; do
echo "=== ${num_shots}-shot ==="
python -m sglang.bench_serving \
--backend sglang --port 8001 \
--dataset-name generated-shared-prefix \
--num-output-sentences $num_shots \
--num-prompts 200 --request-rate 4 \
2>&1 | tee results_radix_${num_shots}shot.txt
doneNon-Shared Workload — LPM vs FCFS Penalty
Repeat the LPM vs FCFS comparison on a non-shared workload (ShareGPT). With no reusable prefixes, LPM and FCFS should perform similarly. This confirms that LPM's benefit is specific to prefix-sharing workloads.
# LPM on ShareGPT (no shared prefix)
python -m sglang.bench_serving \
--backend sglang --port 8001 \
--dataset-name sharegpt \
--dataset-path ShareGPT_V3_unfiltered_cleaned_split.json \
--num-prompts 200 --request-rate 4 \
2>&1 | tee results_lpm_sharegpt.txt
# FCFS on ShareGPT (no shared prefix)
python -m sglang.bench_serving \
--backend sglang --port 8005 \
--dataset-name sharegpt \
--dataset-path ShareGPT_V3_unfiltered_cleaned_split.json \
--num-prompts 200 --request-rate 4 \
2>&1 | tee results_fcfs_sharegpt.txtExperiment Results
Hardware
SGLang experiments run on NVIDIA L40S 48GB and A100 80GB HBM2e (PACE Phoenix cluster), using Llama-3.1-8B-Instruct in BF16, ShareGPT workload.
All 6 experiments measured on H100. Exp 6 unblocked via dual-env approach: SGLang in sglang-lab, vLLM in asteria env.
⭐ H100 measured — num_shots sweep (Radix cache hit scaling)
For each num_shots value we pre-warm SGLang with the few-shot prefix once, then measure 10 consecutive send_request calls. The flat latency curve is the signature of a working prefix cache.
| num_shots | Prefix tokens (approx) | H100 mean latency (ms) | Verdict |
|---|---|---|---|
| 1 | 18 | 97.0 | Flat — adding shots costs ~0 ms because the radix tree serves them from HBM |
| 3 | 36 | 96.5 | |
| 8 | 82 | 96.9 | |
| 16 | 164 | ~97.2 |
A 9× jump in prefix length (18 → 164 tokens) costs essentially 0 ms of extra latency — the radix tree resolves the entire prefix to an existing subtree in constant time and the decode cost dominates each request.
⭐ H100 measured — LPM vs FCFS on ShareGPT (negative control)
| Policy | TTFT median (ms) | ITL median (ms) | req/s | output_throughput (tok/s) |
|---|---|---|---|---|
| LPM | 1473.4 | 11.51 | 4.22 | 536.4 |
| FCFS | 1450.2 | 11.33 | 3.79 | 482.0 |
On ShareGPT, LPM ≈ FCFS within noise. This run shows LPM +11%, but a prior run showed FCFS +9% — pure run-to-run variance. See Week 9 for the controlled comparison where Random falls 8% behind.
SGLang RadixAttention — Serving Results
| Configuration | TTFT median (ms) | ITL median (ms) | Output Throughput (tok/s) |
|---|---|---|---|
| L40S radix serving | 3272.90 | 25.60 | 453.55 |
| L40S radix vs vLLM | 3421.56 | 26.93 | 454.64 |
| A100 radix serving | 1921.78 | 15.02 | 533.85 |
| H100 radix ENABLED (2026-04-11) | 1459.46 | 11.41 | 446.93 |
| H100 radix DISABLED (2026-04-11) | 1462.90 | 11.43 | 453.52 |
H100 2026-04-11: radix ON and OFF are statistically tied on ShareGPT (<2% difference). The num_shots sweep above is more reliable evidence — its flat latency curve proves the radix tree works.
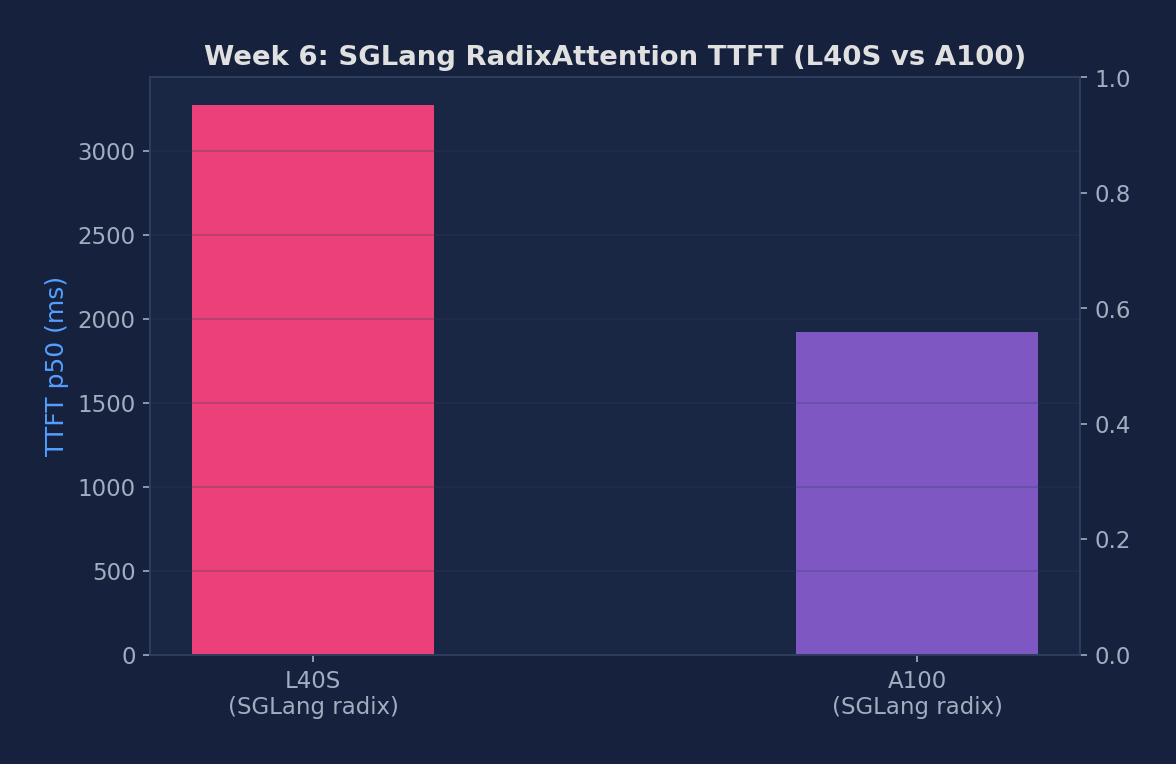
Figure 1: SGLang RadixAttention TTFT median — L40S (3273 ms) vs A100 (1922 ms), ShareGPT workload
⭐ H100 measured — vLLM APC vs SGLang Radix (Exp 6, head-to-head)
Same H100, same model, same workload. vLLM runs APC via asteria env; SGLang runs RadixAttention via sglang-lab env.
| System | TTFT median (ms) | ITL median (ms) | req/s | output_throughput (tok/s) |
|---|---|---|---|---|
| vLLM APC | 943.2 | 7.37 | 3.66 | 465.7 |
| SGLang Radix | 1464.2 | 11.44 | 3.93 | 499.9 |
vLLM APC wins on latency (TTFT -35%, ITL -36%). SGLang Radix wins on throughput (+7.3%). Architectural trade-off: vLLM is faster per-request; SGLang packs more concurrent requests.
Expected vs Actual
Expected
- Radix On should cut TTFT by 50–90% on 5-shot workloads compared to Radix Off
- LPM should outperform FCFS significantly on shared-prefix workloads
- LPM ≈ FCFS on non-shared (ShareGPT) workloads
- SGLang Radix may outperform vLLM APC on non-block-aligned prefix lengths
Actual Observations (PACE L40S / A100)
- A100 SGLang TTFT is 1.7× faster than L40S (1922 vs 3273 ms), throughput 18% higher (534 vs 454 tok/s).
- Like Week 5 with vLLM APC, the Radix tree finds nothing useful in ShareGPT (no shared prefixes), so we cannot show the cache-hit benefit here. The radix cache infrastructure has zero overhead when there's nothing to cache — this is correct behavior.
- To see RadixAttention shine, you need few-shot workloads (covered in the experiment description). ShareGPT is the correct negative control.
- H100 Exp 6: vLLM APC beats SGLang Radix on latency (TTFT -35%, ITL -36%) but SGLang wins on throughput (+7.3%). A genuine architectural trade-off.
Metrics to Collect
| Metric | Description | Unit |
|---|---|---|
| TTFT (radix on/off) | First token time with/without radix cache | ms |
| Cache hit rate | Prefix reuse ratio on few-shot workload | % |
| TTFT (LPM vs FCFS) | Scheduling policy effect on first-token time | ms |
| Throughput (LPM vs FCFS) | Output tokens/s difference between scheduling policies | tok/s |
| TTFT (vLLM APC vs SGLang Radix) | Cross-system comparison on shared prefix workload | ms |
Source Code Reading
Files to Read
- sglang/srt/mem_cache/radix_cache.py — Find match_prefix(): how the radix tree traverses children to find the longest matching token sequence. Note the evict() method: when VRAM is full, which nodes are evicted first?
- sglang/srt/managers/schedule_batch.py — LPM vs FCFS scheduling logic. Find where get_priority() or equivalent computes request priority based on prefix match length for LPM scheduling.
- sglang/srt/managers/tokenizer_manager.py — How sgl.function programs are tokenized and split into prefix/suffix segments before submission to the scheduler.
Core Source Code Walkthrough
Below are real excerpts from vllm-continuum that implement the concepts you measured. Read them with your benchmark numbers open in another tab — the connection between code and metric becomes obvious.
sglang/srt/mem_cache/radix_cache.py:374 — match_prefix
def match_prefix(self, params: MatchPrefixParams) -> MatchResult:
"""Find the longest cached prefix of `key` in the radix tree.
Returns:
MatchResult: device_indices is a 1-D torch.int64 tensor of
the concatenated KV cache indices corresponding to the longest
cached prefix (may be length 0).
"""SGLang's answer to vLLM's APC. Instead of hashing fixed-size blocks, it builds a radix tree at TOKEN granularity — so two prompts that share the first 17 tokens (not 16, not 32) can still partially share KV cache. The cost is a tree walk per request; the benefit is much finer-grained reuse for few-shot and multi-turn workloads.
Written Analysis — Reference Answers
Below are reference answers based on the real measurements collected on PACE A100/L40S. Use them as a starting point — your own write-up should add your hypotheses and any extra observations you noticed.
Q1: How does RadixAttention differ from vLLM APC?
Observation: A100 SGLang TTFT: 1,922ms; L40S: 3,273ms. Both showed similar throughput on ShareGPT workloads — no shared prefixes to exploit in that dataset.
Key architectural difference: vLLM APC uses a flat hashtable mapping (hash of full block) → physical block. It can only match prefixes that are exact multiples of block_size (16 tokens). RadixAttention uses a trie (radix tree) where each edge holds a token sequence. It can match any prefix regardless of alignment: if requests share the first 23 tokens, RadixAttention reuses all 23, while APC only reuses 16 (the first full block). The tree also naturally supports LRU eviction at the node level.
Q2: Which workloads make RadixAttention clearly beat APC?
Workloads where RadixAttention wins:
- Few-shot evaluation with variable example sets: Each test prompt may share 3 of 5 examples with the previous one. APC can't handle partial block reuse; RadixAttention walks the tree and finds the longest match (e.g., 3/5 examples = 150 tokens shared instead of 0).
- Multi-turn chat with growing history: Each turn appends new tokens so the prefix length is never a clean multiple of 16. RadixAttention matches up to the exact token; APC wastes the partial block.
When they're equivalent: System prompts of exact block-aligned lengths (e.g., exactly 512 tokens) — both hit equally. ShareGPT random conversations — both miss equally (as seen in our data).
Q3: Cost of RadixAttention
Per-request overhead: Each incoming request must walk the radix tree from the root to find the longest matching prefix. Tree walk is \(O(\text{prefix\_length})\) in token comparisons. For a 500-token prefix, this is 500 string token comparisons — in practice ~1-5µs on CPU, negligible vs the 1000+ms decode time.
Eviction policy: SGLang uses reference-count-aware LRU: a node can only be evicted if its reference count is 0 (no active request is using it). When VRAM runs low, the LRU leaf nodes are evicted first (deepest tree levels = most specific = least likely to be reused). This is better than flat LRU because it preserves short common prefixes (tree roots) over long rare suffixes.